Nur Lokales ist Wahres - Teil 1 (WebDev)
Wie schlagen sich lokale Open-Source-Modelle gegen die großen Cloud-Giganten bei der Webentwicklung? Ein Praxistest.

Im Vorwort dieser Serie haben wir bereits erläutert, warum der blinde Flug in die Cloud-Abhängigkeit für Unternehmen langfristig riskant sein kann. Doch wie schlagen sich lokal betriebene Modelle in der Praxis? Genau das testen wir in diesem ersten Teil. Das Ziel: Die Erstellung einer vollständigen, responsiven Website für ein fiktives Café namens KOOKIZ.
Um realistische und vor allem für Unternehmen greifbare Bedingungen zu schaffen, haben wir uns für ein spezifisches, faires Test-Setup entschieden.
Unser Tech-Stack: Leistung, die man sich auf den Schreibtisch stellen kann
Für das Hosting unserer lokalen Modelle nutzen wir eine NVIDIA RTX 6000 Ada, die wir über Runpod.io gemietet haben. Warum genau diese Karte? Weil sie preislich und von den Spezifikationen her einer Hardware entspricht, die für Endnutzer und mittelständische Unternehmen bezahlbar ist und problemlos im eigenen Büro betrieben werden kann – ohne ein eigenes Rechenzentrum bauen oder waghalsige IT-Abenteuer eingehen zu müssen.
Die Specs der NVIDIA RTX 6000 Ada Generation im Überblick:
- VRAM: 48 GB GDDR6 (ausreichend, um auch größere Modelle lokal mit guter Geschwindigkeit laufen zu lassen)
- CUDA-Kerne: 18.176
- Leistungsaufnahme: ca. 300 Watt
Zum Vergleich: Moderne High-End-Rechner aus dem Jahr 2026, wie etwa der Mac Studio mit Unified Memory, aktuelle High-End MacBooks oder spezialisierte AI-PCs wie der Spark, bieten ähnliche oder sogar teilweise größere Speicherkapazitäten für KI-Anwendungen, da sie ihren Arbeitsspeicher dynamisch als VRAM nutzen können. Die Leistung der RTX 6000 Ada zeigt uns jedoch sehr realitätsnah, was dedizierte Profi-Hardware "unter dem Schreibtisch" heute zu leisten imstande ist.
Die Coding-Umgebung: Gleiche Bedingungen für alle
Als Coding-Umgebung verwenden wir Pi.Dev direkt in Visual Studio Code.
An dieser Stelle drängt sich natürlich die Frage auf: Warum nutzen wir nicht einfach Claude Code mit Claude oder Gemini in Antigravity?
Die Antwort ist simpel: Wir wollen die Modelle in der exakt gleichen Umgebung testen. Wie der kürzliche Leak von Claude Code noch einmal eindrucksvoll verdeutlicht hat, ist es nicht nur die reine Qualität des Modells, die über das Endergebnis entscheidet. Viel entscheidender ist oft der sogenannte "Harness" – also die Umgebung, in die das Modell eingebettet ist und die ihm Kontext, Systemprompts und Werkzeuge zur Verfügung stellt.
Für einen wirklich fairen Test haben wir uns daher für Pi.Dev entschieden, da es eine sehr minimale Vorkonfiguration aufweist und dem Modell nicht heimlich unter die Arme greift.
Wir haben allen Modellen den exakt gleichen Ausgangsprompt gegeben: Eine kurze Anleitung für die Website, die nur grob den Namen, die Speisekarte und unsere Corporate Colors enthielt.
Hier ist der Prompt, mit dem alle Probanden starten mussten:
## KOOKIZ - Cookies and Cafe website
Build a multi page website for **KOOKIZ**, a modern and playful cafe.
Incorporate all the sections necessary that are vital to a complete and modern website.
**KOOKIZ** is a playful brand. Our brand colours are "#5ce1e6", "#fff859", "#1a1a1a".
Be creative.
Make it "mobile first". The Design MUST be respnosive.
### MENU:
**Cookies**
| Item | Description | Price |
|------|-------------|-------|
| Classic Choco Chip | The OG. Crispy edges, gooey center. | €2.50 |
| Double Trouble | Double chocolate, double regret. | €3.00 |
| Peanut Butter Dream | Nutty, dense, dangerously good. | €2.80 |
| Matcha White Choc | Green tea meets sweetness. | €3.20 |
| Salted Caramel Bliss | Sweet, salty, absolutely filthy. | €3.00 |
**Drinks**
| Item | Description | Price |
|------|-------------|-------|
| Specialty Latte | House blend espresso, silky milk. | €4.00 |
| Iced Matcha | Ceremonial grade, oat milk. | €4.50 |
| Fresh Lemonade | Made daily, never from concentrate. | €3.50 |
| Hot Chocolate | Dark, rich, winterproof. | €3.80 |
**Specials**
| Item | Description | Price |
|------|-------------|-------|
| Cookie + Drink Combo | Any cookie with any drink. | €5.50 |
| Box of 6 | Mix & match your favorites. | €13.00 |
| Kookiz Mystery Box | Surprise selection, always worth it. | €10.00 |
### Contact
- 📍 Kookizstraße 42, 44137 Dortmund
- 📞 +49 231 987 654 3
- 📧 hello@kookiz.de
- 🕐 Mon–Fri 08:00–19:00, Sat–Sun 09:00–18:00
### Tech stack you MUST use:
- Next.js
- tailwind css
- lucide react icons
### FORBIDDEN:
- Emojis
Wer tritt in den Ring?
Auf Seiten der großen Cloud-Modelle bemühen wir die aktuellen Flaggschiffe der großen Anbieter:
- Claude Opus 4.6 (Anthropic)
- GPT-5.5 (OpenAI)
- Gemini 3.1-Pro-Preview (Google)
Diesen Goliath-Modellen stellen sich zwei hochaktuelle Open-Weight-Modelle entgegen: Gemma 4 (ebenfalls von Google entwickelt) und Qwen 3.6 von Alibaba. Die Wahl fiel ganz bewusst auf diese zwei, da sie (Stand Mai 2026) zu den neuesten Modellen auf dem Markt gehören und in den Open-Source-Communities viel Lob für ihre Leistungsfähigkeit einheimsen.
Um die Open-Source-Modelle lokal mit maximaler Performance bereitzustellen, setzen wir als Inference-Engine vLLM ein. Damit sie auf unserer Hardware optimal lauffähig sind, haben wir uns konkret für diese Versionen und Quantisierungen entschieden:
- Gemma 4:
gemma4-31B-AWQ-8bitundgemma4-26B-A4B-AWQ-8bit - Qwen 3.6:
Qwen3.6-27B-AWQ-4bitundQwen3.6-35B-A3B-AWQ-4bit
Dense vs. MoE: Warum wir zweigleisig fahren
In unserer Testauswahl finden sich sowohl klassische Dense-Modelle als auch MoE-Architekturen (Mixture of Experts). Doch wo liegt eigentlich der Unterschied?
Bei einem Dense-Modell werden für jeden einzelnen generierten Token stets alle Parameter des neuronalen Netzes aktiviert. Das erfordert bei der Inferenz eine hohe Speicherbandbreite und Rechenleistung, bietet aber eine enorme Reasoning-Kapazität. Die Basis-Varianten von Gemma 4 (31B) und Qwen 3.6 (27B) sind solche klassischen Dense-Modelle.
Im Gegensatz dazu aktivieren MoE-Modelle für jeden Token immer nur ganz spezifische Sub-Netzwerke (die sogenannten "Experten") – also nur einen Bruchteil der gesamten Parameter. So kann ein Modell wie das Qwen 3.6 35B insgesamt zwar über 35 Milliarden Parameter verfügen, nutzt für die Vorhersage des nächsten Zeichens aber nur 3 Milliarden (gekennzeichnet durch den Zusatz A3B). Das gleiche Prinzip greift beim Gemma 4 26B A4B. Der entscheidende Vorteil: Diese Modelle sind trotz ihres enormen Wissensschatzes rasend schnell und hocheffizient, was sie für den lokalen Betrieb prädestiniert.
Wir testen in diesem Setup ganz bewusst beide Architekturen, um herauszufinden, ob die effizienteren MoE-Netze bei komplexen Web-Development-Aufgaben bereits mit den schwereren Dense-Modellen mithalten können.
Wie wurde der Test durchgeführt?
Die Durchführung des Tests war denkbar simpel und pragmatisch: Wir haben den oben gezeigten Plan bzw. Prompt direkt an das Modell übergeben – mit der einfachen Anweisung, die Website exakt wie beschrieben zu bauen.
Es gab während des Prozesses kein manuelles Eingreifen, kein schrittweises Debugging unsererseits und keine nachträglichen Korrekturen. Jedes Modell musste die Anwendung in einem einzigen, direkten Durchlauf eigenständig aufbauen. Nur so lässt sich die ungeschönte, rohe Leistungsfähigkeit der verschiedenen Systeme unter absolut gleichen Bedingungen vergleichen.
Die Ergebnisse: Wer baut das beste Café?
Wir starten unsere Auswertung mit dem aktuellen Platzhirsch der geschlossenen Modelle: GPT-5.5 von OpenAI.
GPT-5.5 (OpenAI)
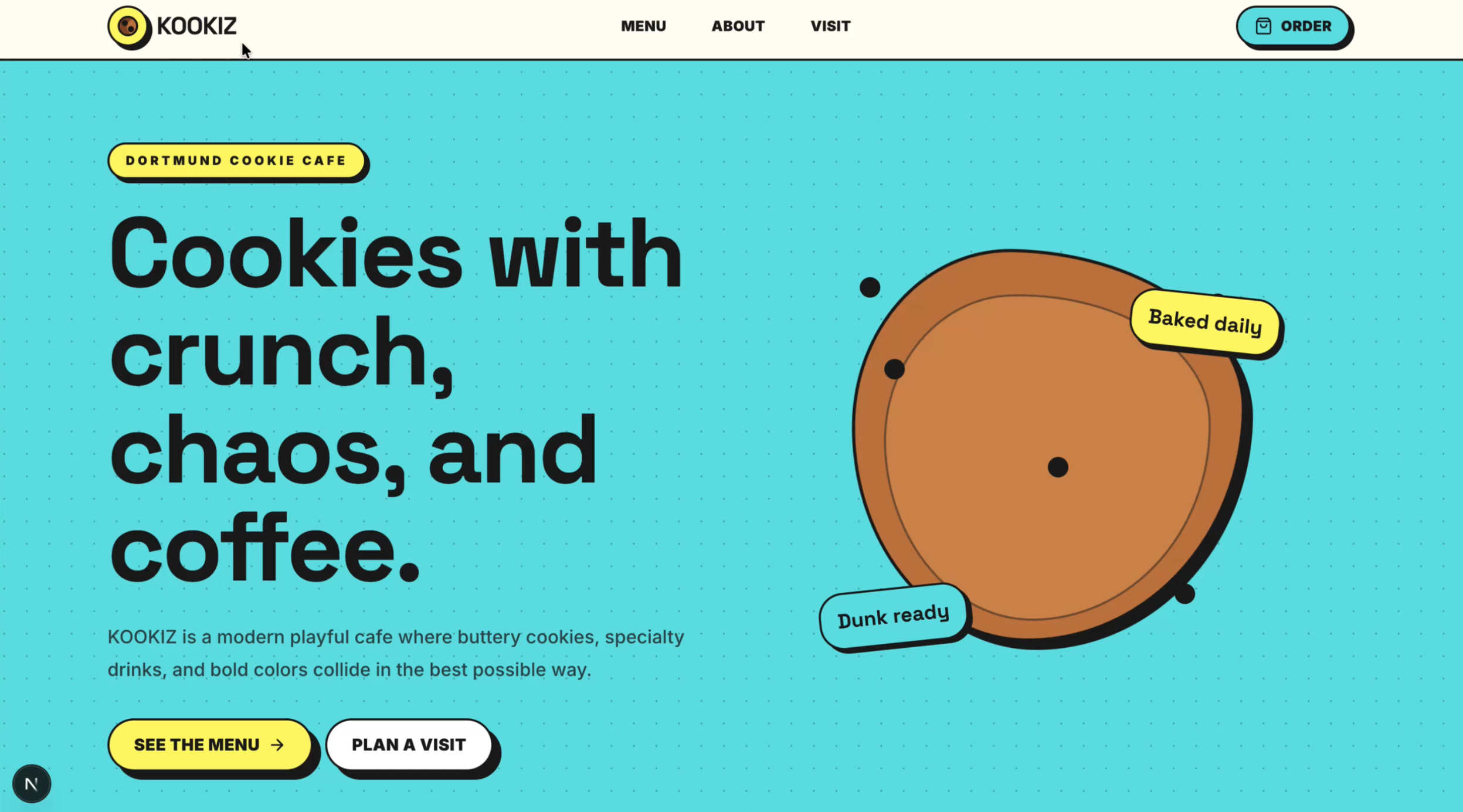 Seite: Landingpage (Abschnitt 1)
Seite: Landingpage (Abschnitt 1)
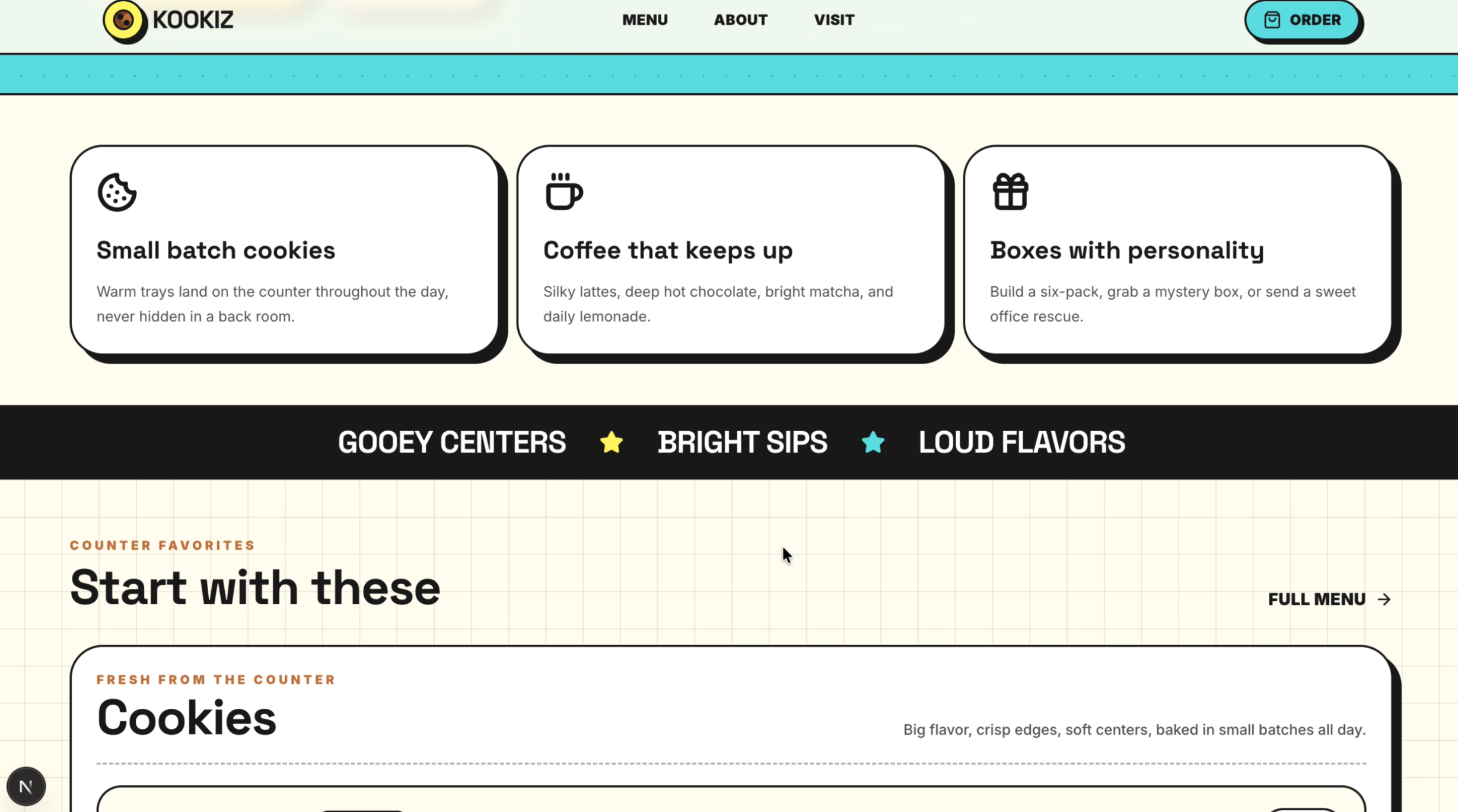 Seite: Landingpage (Abschnitt 2)
Seite: Landingpage (Abschnitt 2)
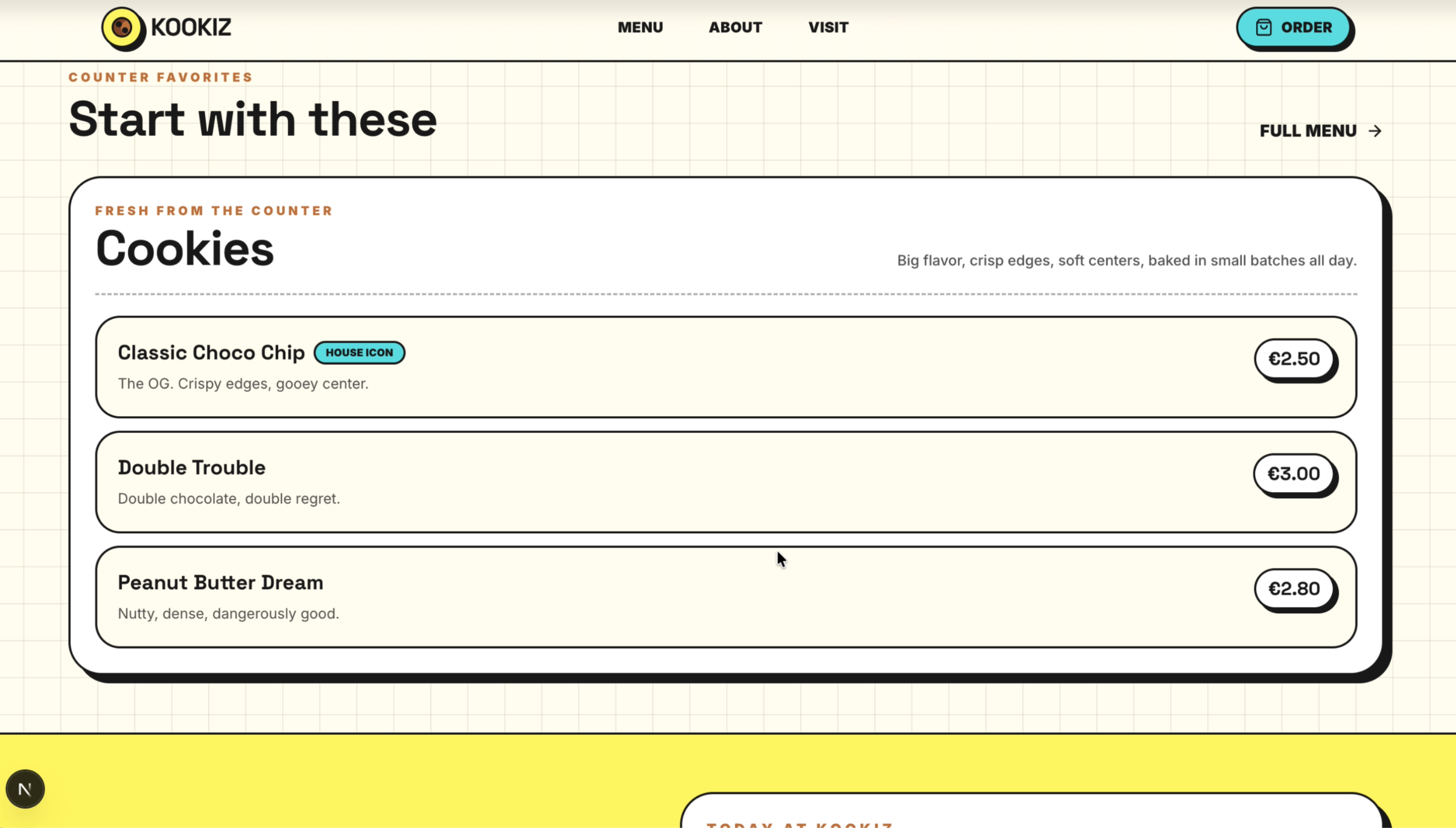 Seite: Landingpage (Abschnitt 3)
Seite: Landingpage (Abschnitt 3)
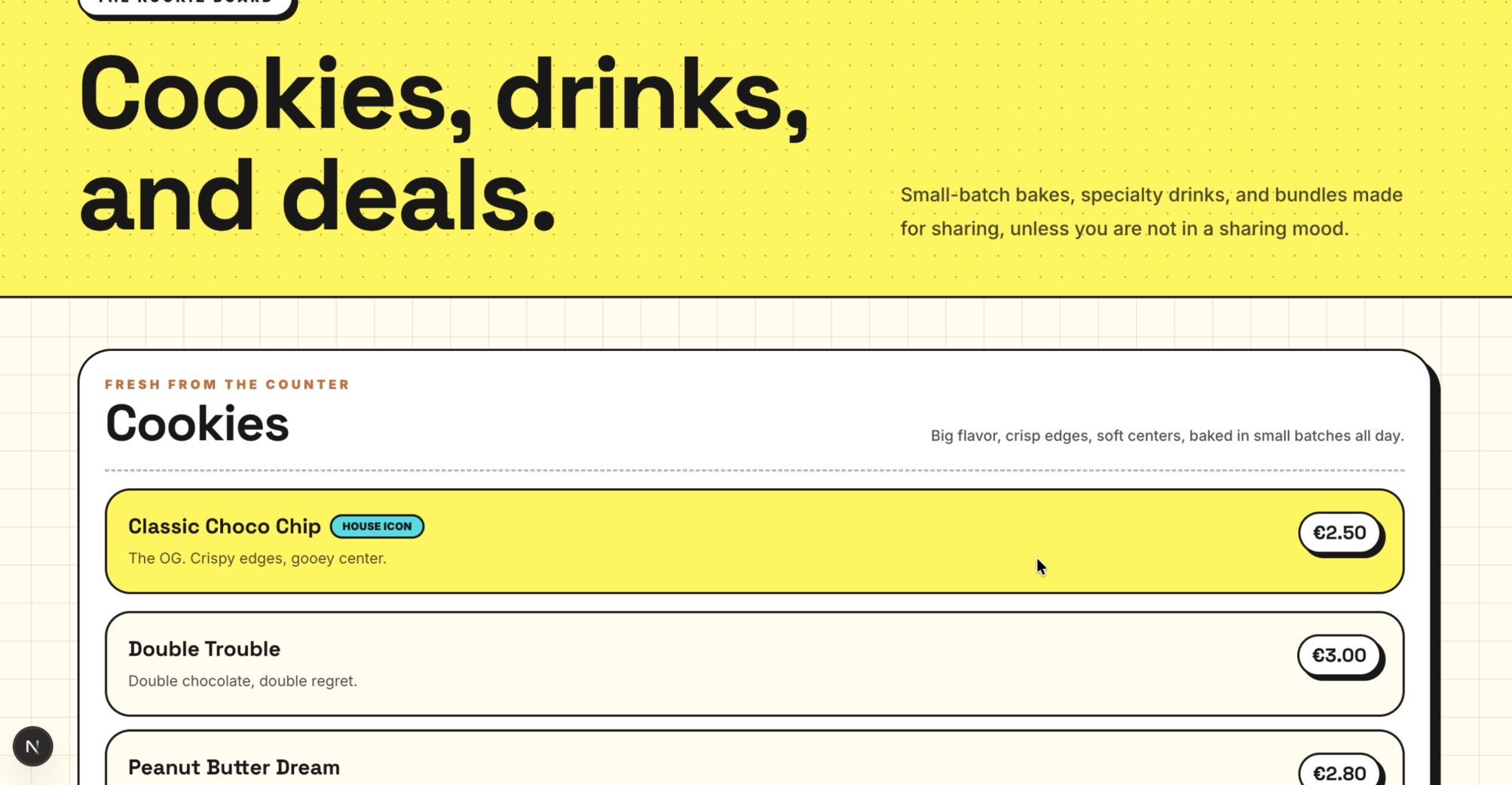 Seite: Menu (Abschnitt 1)
Seite: Menu (Abschnitt 1)
 Seite: Menu (Abschnitt 2)
Seite: Menu (Abschnitt 2)
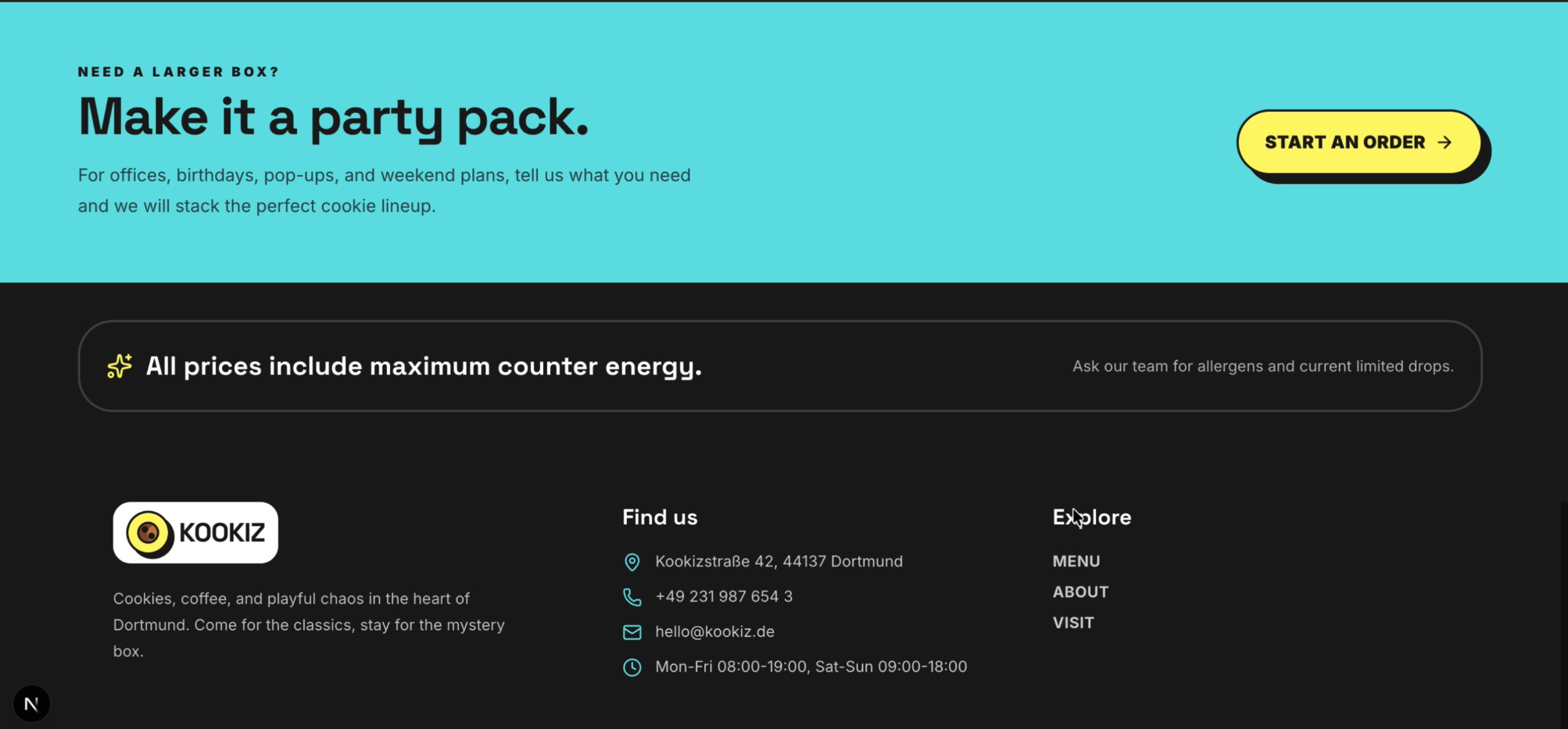 Seite: Menu (Abschnitt 3)
Seite: Menu (Abschnitt 3)
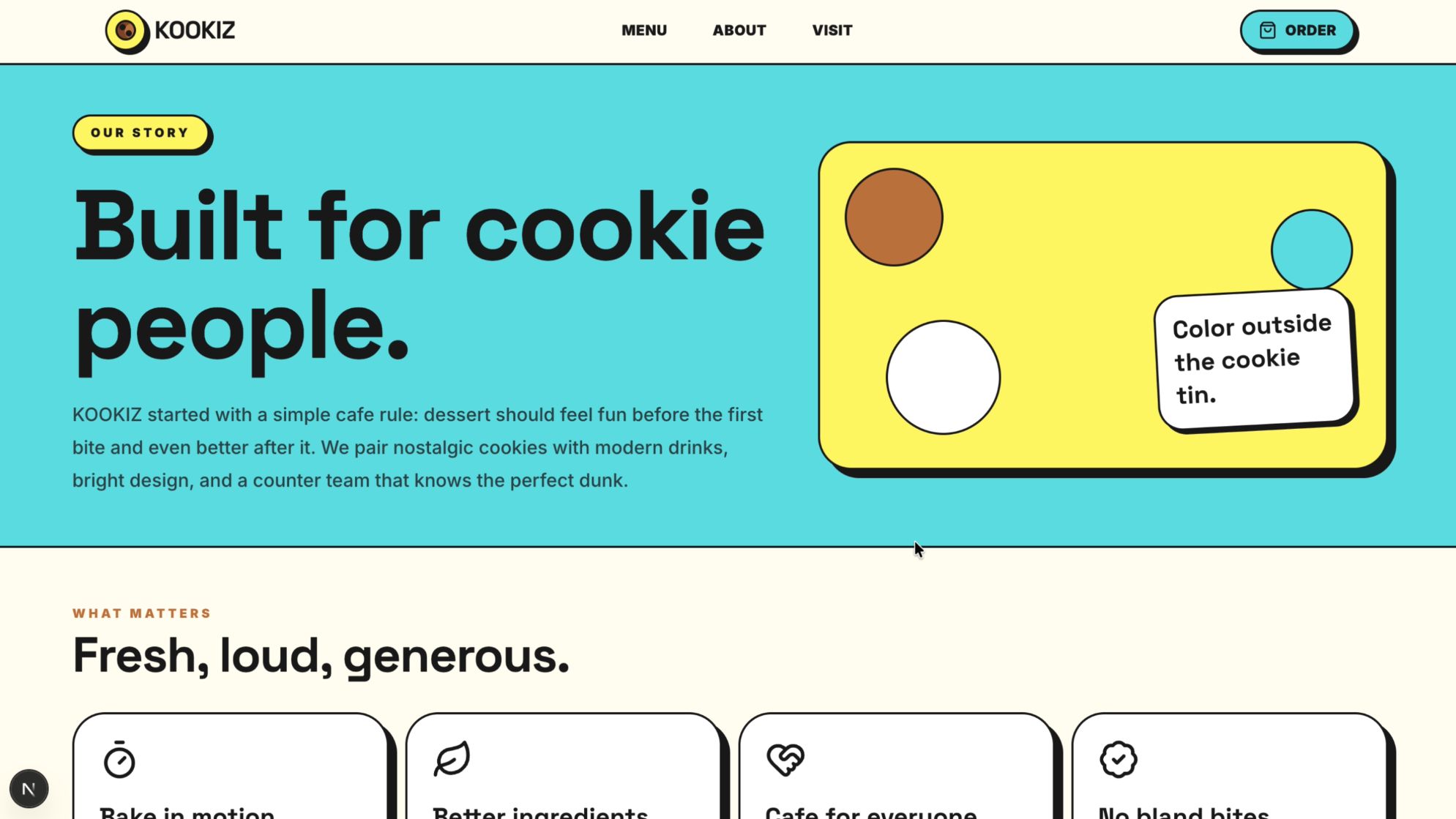 Seite: About (Abschnitt 1)
Seite: About (Abschnitt 1)
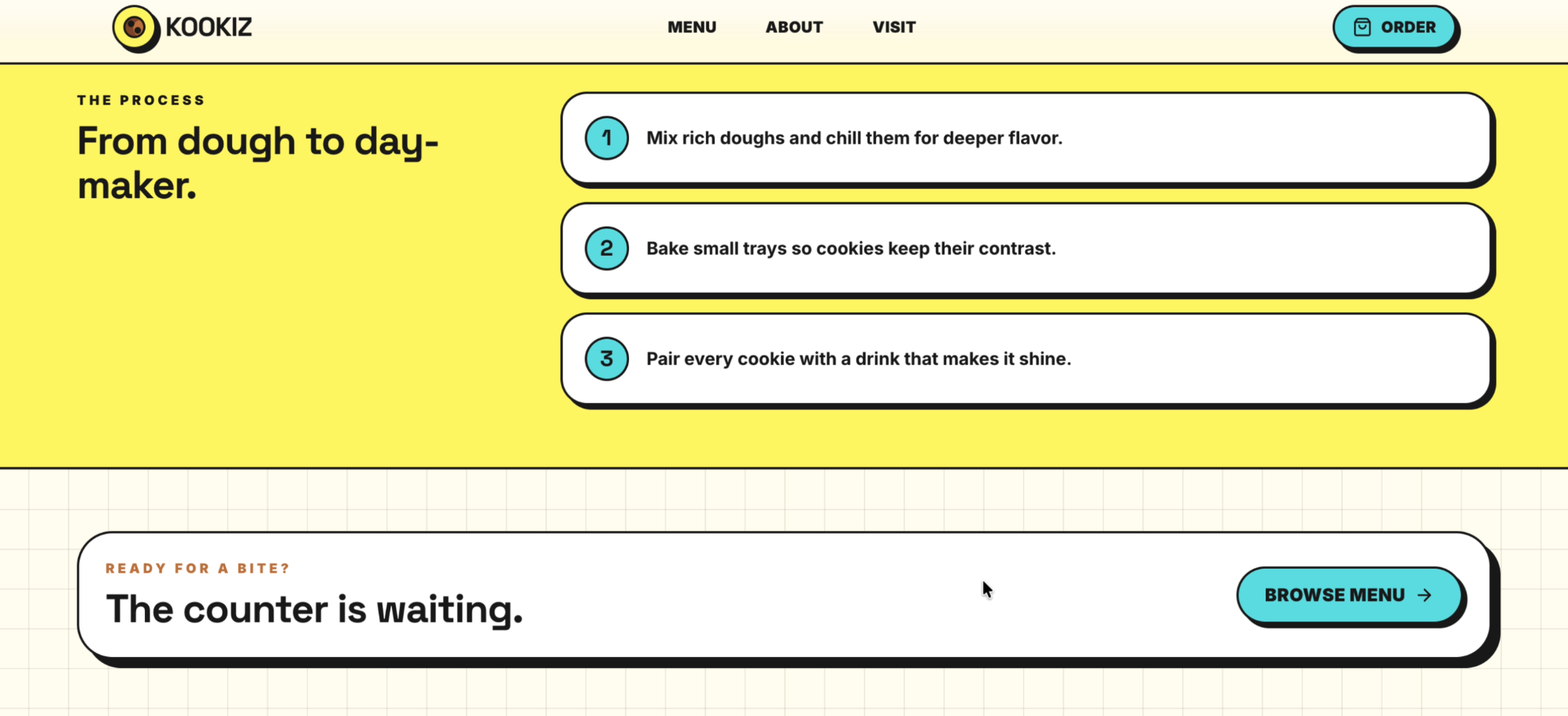 Seite: About (Abschnitt 2)
Seite: About (Abschnitt 2)
GPT-5.5 hat abgeliefert. Das Design ist großartig und fängt den verspielten, modernen Vibe von KOOKIZ perfekt ein. Unsere vorgegebenen Corporate Colors (#5ce1e6, #fff859, #1a1a1a) wurden harmonisch in die Gestaltung eingebunden und verleihen der Website einen professionellen, aber dennoch frischen Look.
Was besonders hervorsticht, ist die einwandfreie Funktionalität "out of the box":
- Design & Layout: Ein visuell ansprechender Aufbau, bei dem alles stimmig wirkt.
- Vorgaben: Alle Anweisungen aus unserem Prompt wurden akkurat umgesetzt. Sowohl das vollständige Menü (Cookies, Drinks, Specials) als auch die Kontaktinformationen wurden lückenlos integriert. Auch das Verbot von Emojis wurde strikt eingehalten.
- Mobile First: Die Website war auf Anhieb vollständig responsiv ("mobile-compatible right away") und ließ sich auf mobilen Endgeräten problemlos bedienen.
- Navigation: Das Routing und die interne Navigation zwischen den Seiten funktionierten absolut reibungslos, ohne dass wir im Code nachbessern mussten.
Einen kleinen Abstrich müssen wir jedoch machen: Der Cookie, den GPT-5.5 in der Hero-Section zu kreieren versucht hat, ist optisch etwas misslungen.
Kostenpunkt: Die gesamten API-Kosten für die vollständige Erstellung dieser Website lagen bei $0,62.
Zusammenfassend lässt sich sagen, dass GPT-5.5 den Auftrag zu vollster zufriedenheit erfüllt hat und darüber hinaus auch noch kreativ Sektionen eingefügt hat, um die Website zu komplettieren.
Gemini 3.1-Pro-Preview (Google)
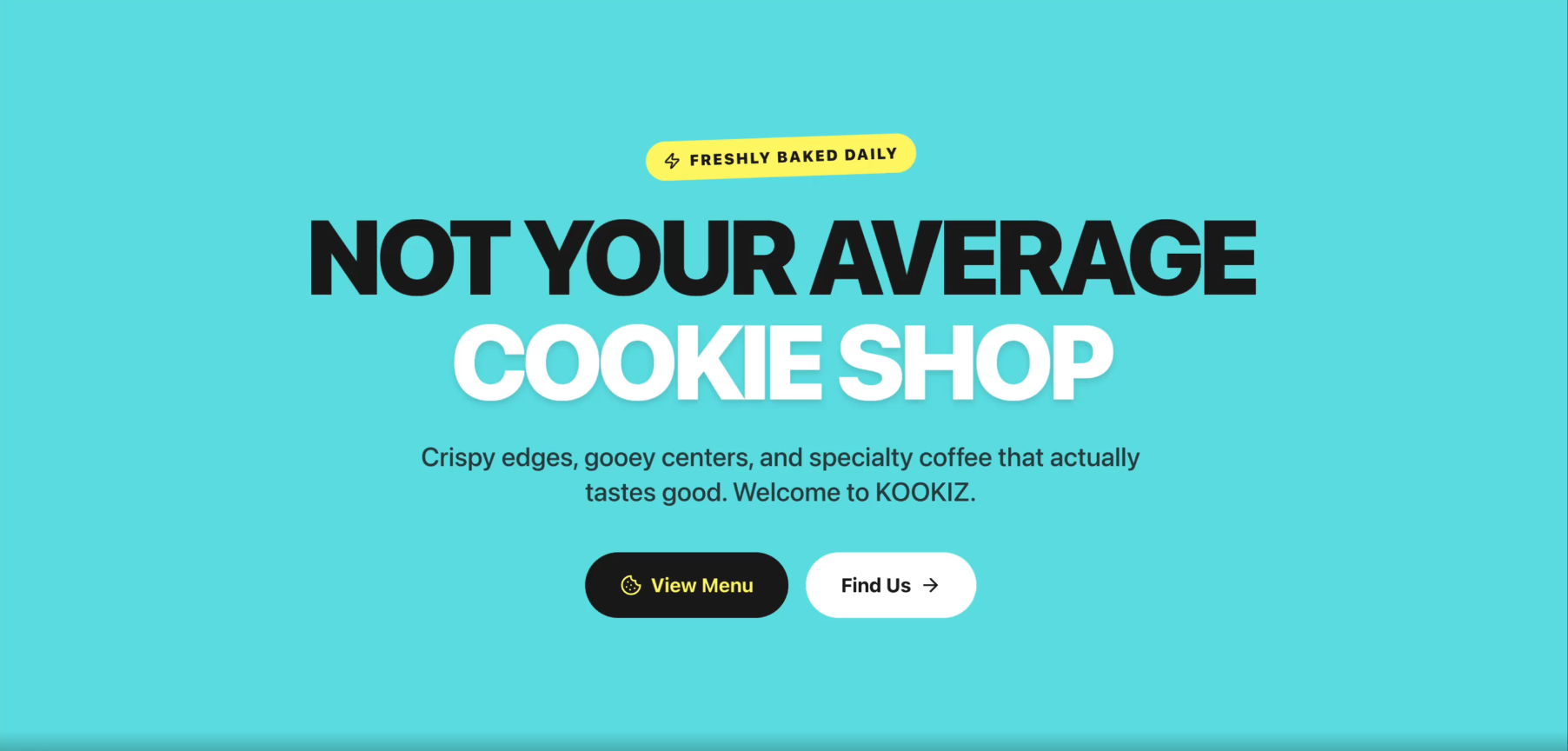
Seite: Landingpage (Abschnitt 1)

Seite: Landingpage (Abschnitt 2)
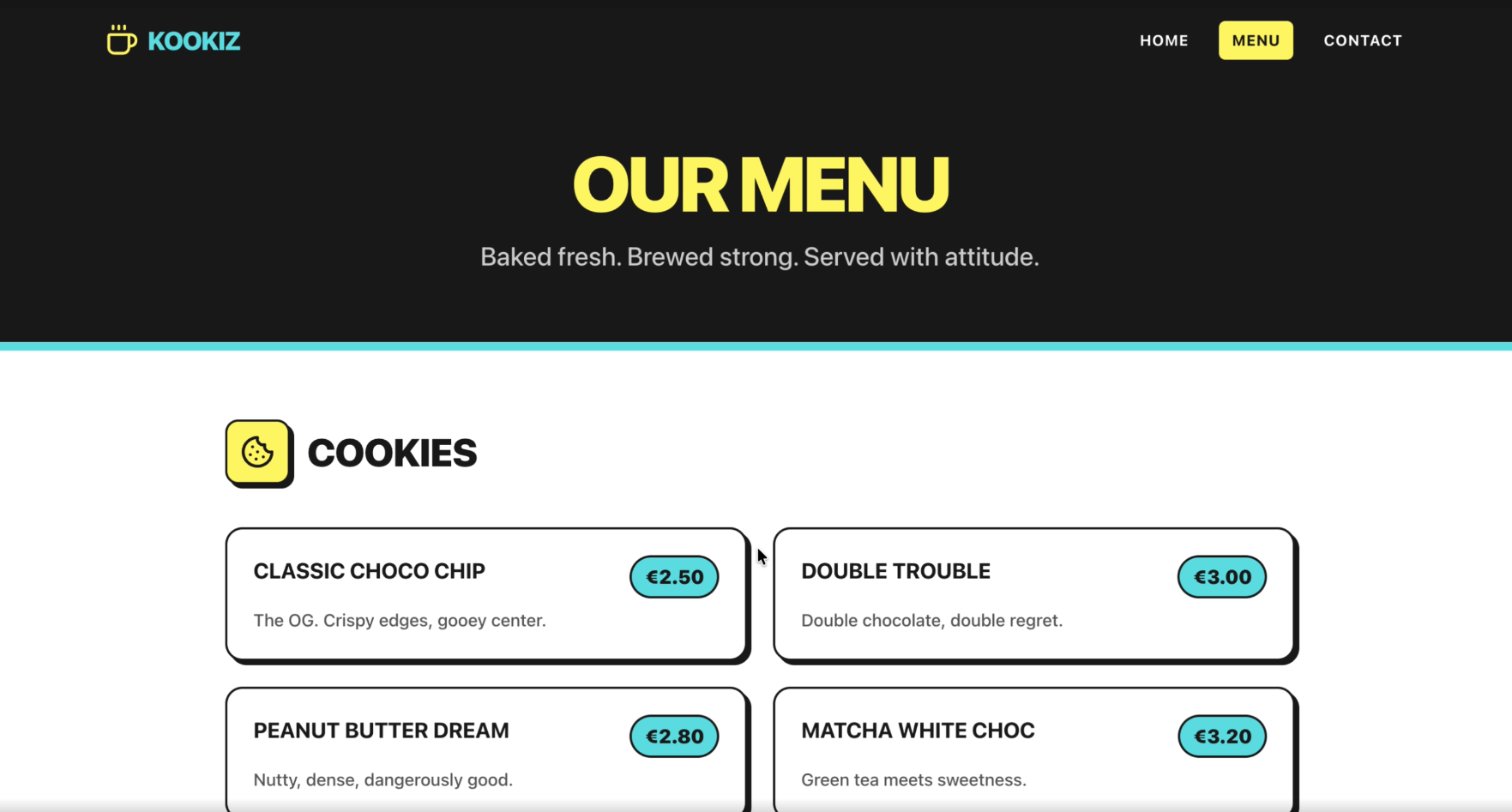
Seite: Menu (Abschnitt 1)
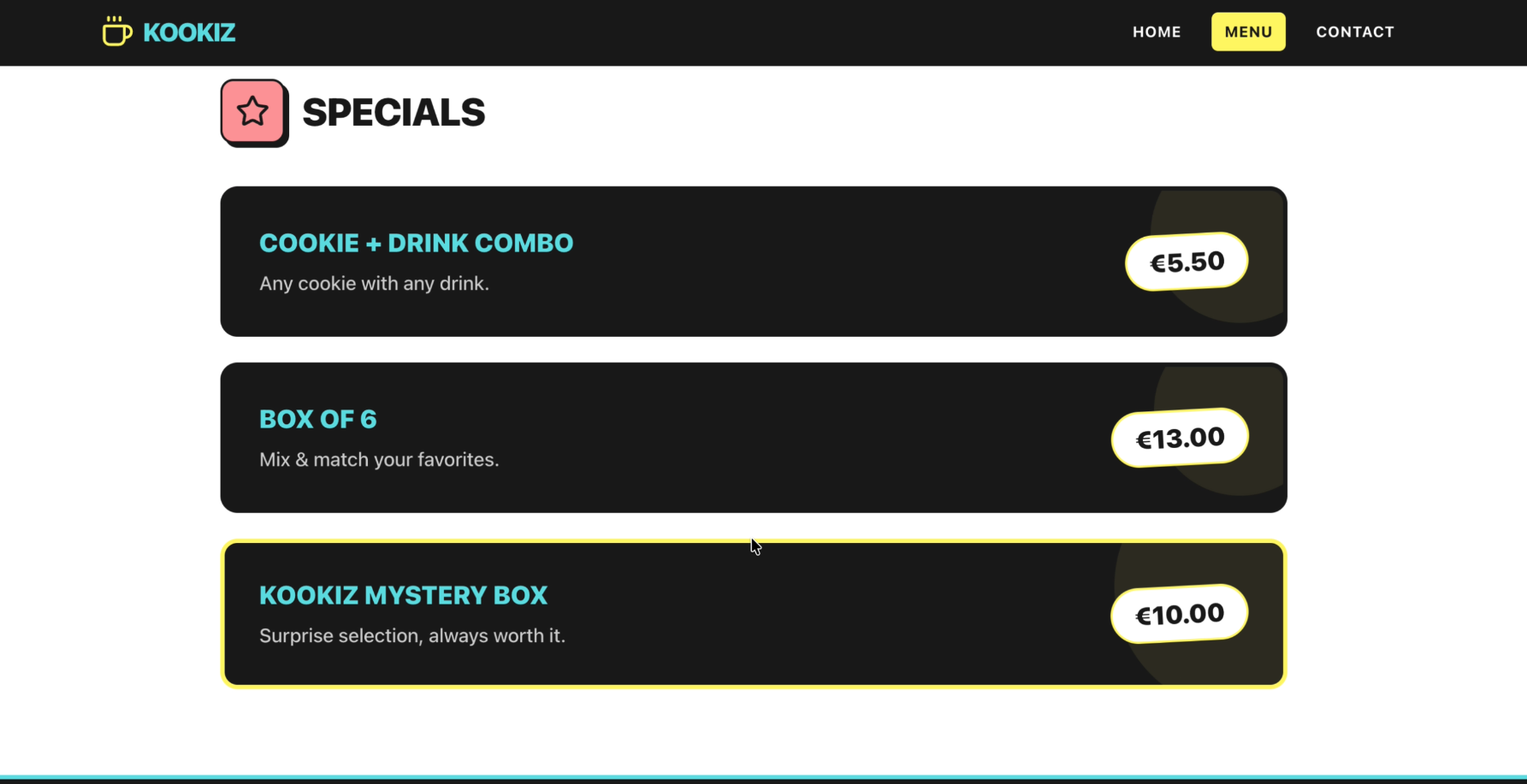
Seite: Menu (Abschnitt 2)
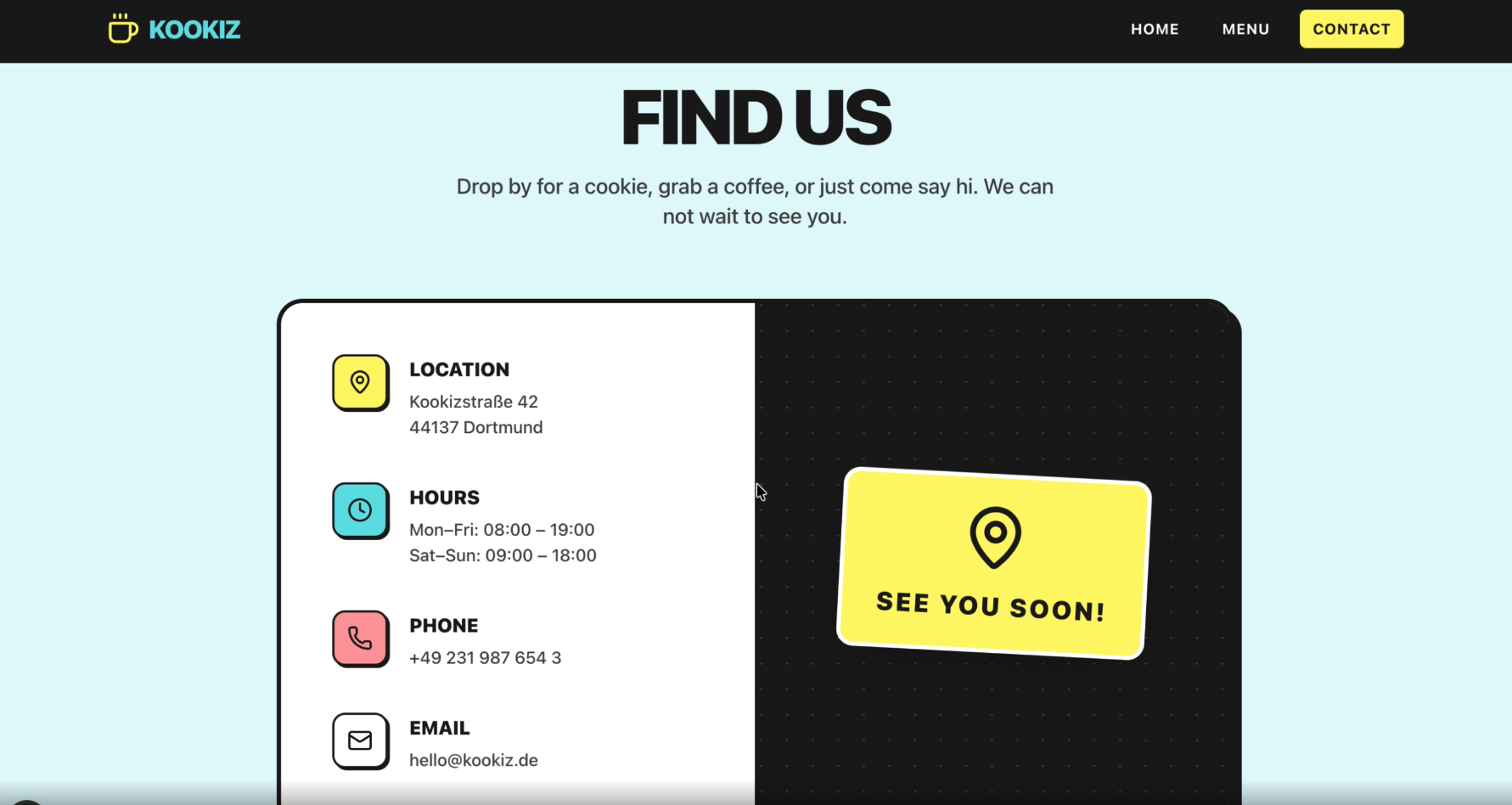
Seite: Contact
Gemini 3.1-Pro-Preview liefert ebenfalls ein absolut brauchbares Ergebnis ab. Die Website ist auf den ersten Blick sauber strukturiert und nutzt die von uns vorgegebene Farbpalette stimmig.
Allerdings fällt im direkten Vergleich mit GPT-5.5 sofort auf, dass das Design von Gemini deutlich konservativer und weniger verspielt wirkt. Während OpenAI eine echte "Wow"-Hero-Section gezaubert hat, beschränkt sich Gemini auf ein grundsolides, aber stark standardisiertes Web-Layout. Die Kreativität kommt hier etwas zu kurz.
Was uns noch aufgefallen ist:
- Vorgaben & Funktionalität: Auch hier wurden unsere strikten Vorgaben lückenlos und funktionsfähig umgesetzt.
- Umfang & Details: Die generierte Website ist insgesamt etwas knapper und weniger detailliert als der Entwurf von GPT-5.5.
- Design-Elemente: Anstatt auffällige UI-Elemente einzubauen, verlässt sich Gemini auf klare Box-Layouts, kräftige Buttons und einfache Typografie.
Kostenpunkt: Die API-Kosten für die Erstellung der Website lagen bei unschlagbaren $0,35.
Fazit: Gemini 3.1-Pro-Preview ist ein absolut verlässlicher "Arbeiter". Wer ein funktionales Grundgerüst sucht, wird hier fündig – auch wenn man für das "gewisse Etwas" im Design selbst noch Hand anlegen muss.
Claude Opus 4.6 (Anthropic)

Seite: Landingpage (Abschnitt 1)
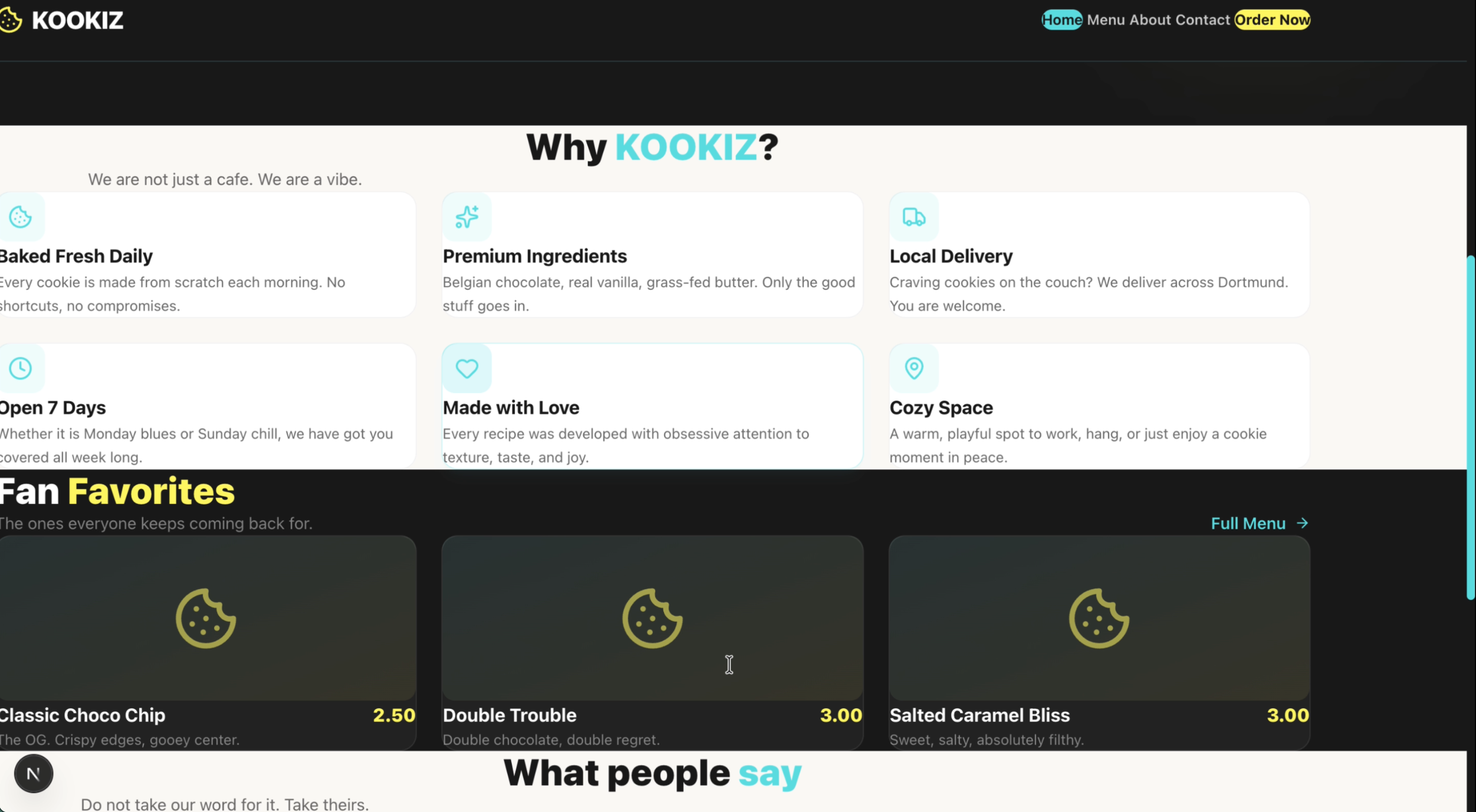
Seite: Landingpage (Abschnitt 2)
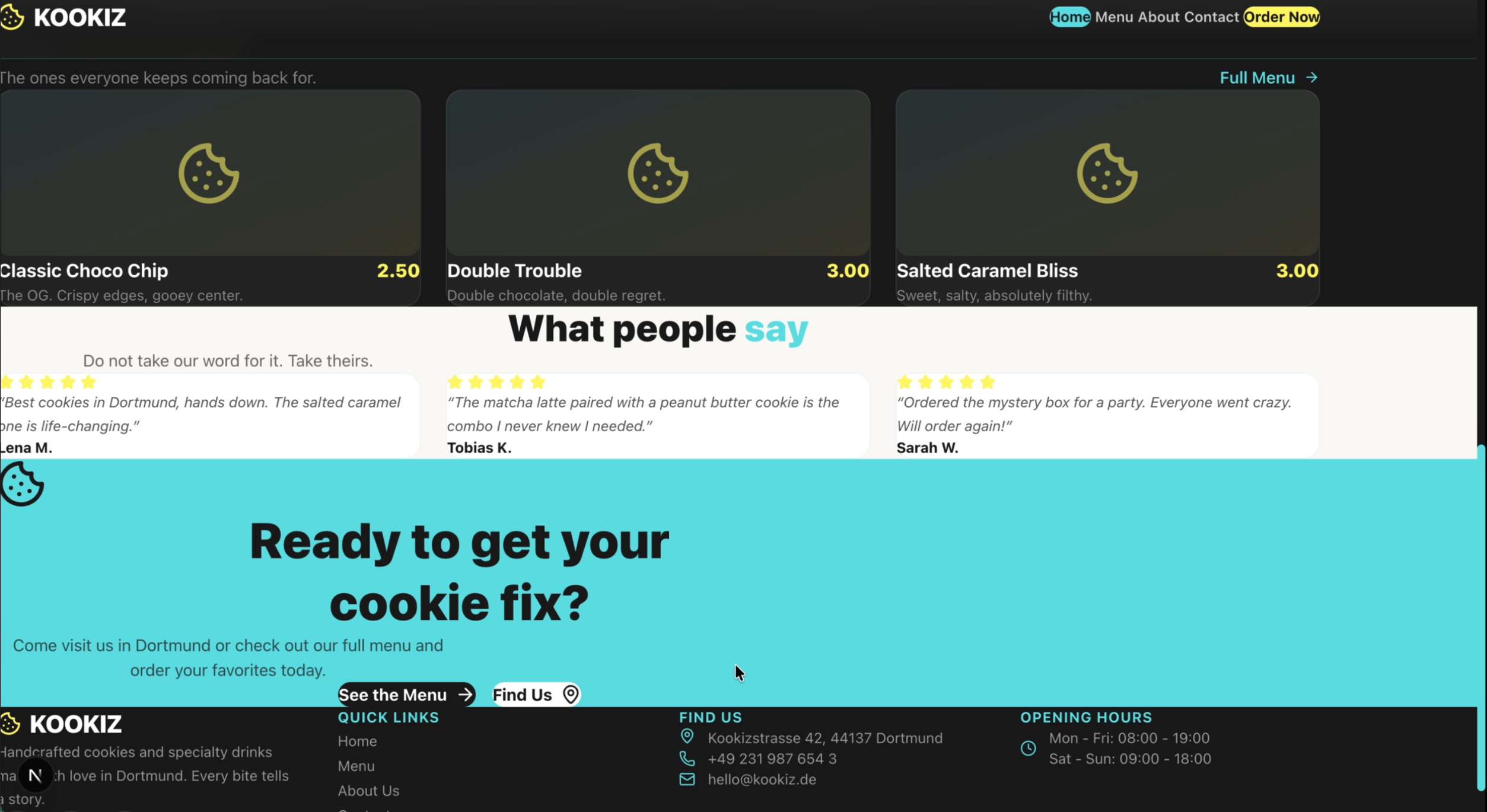
Seite: Landingpage (Abschnitt 3)
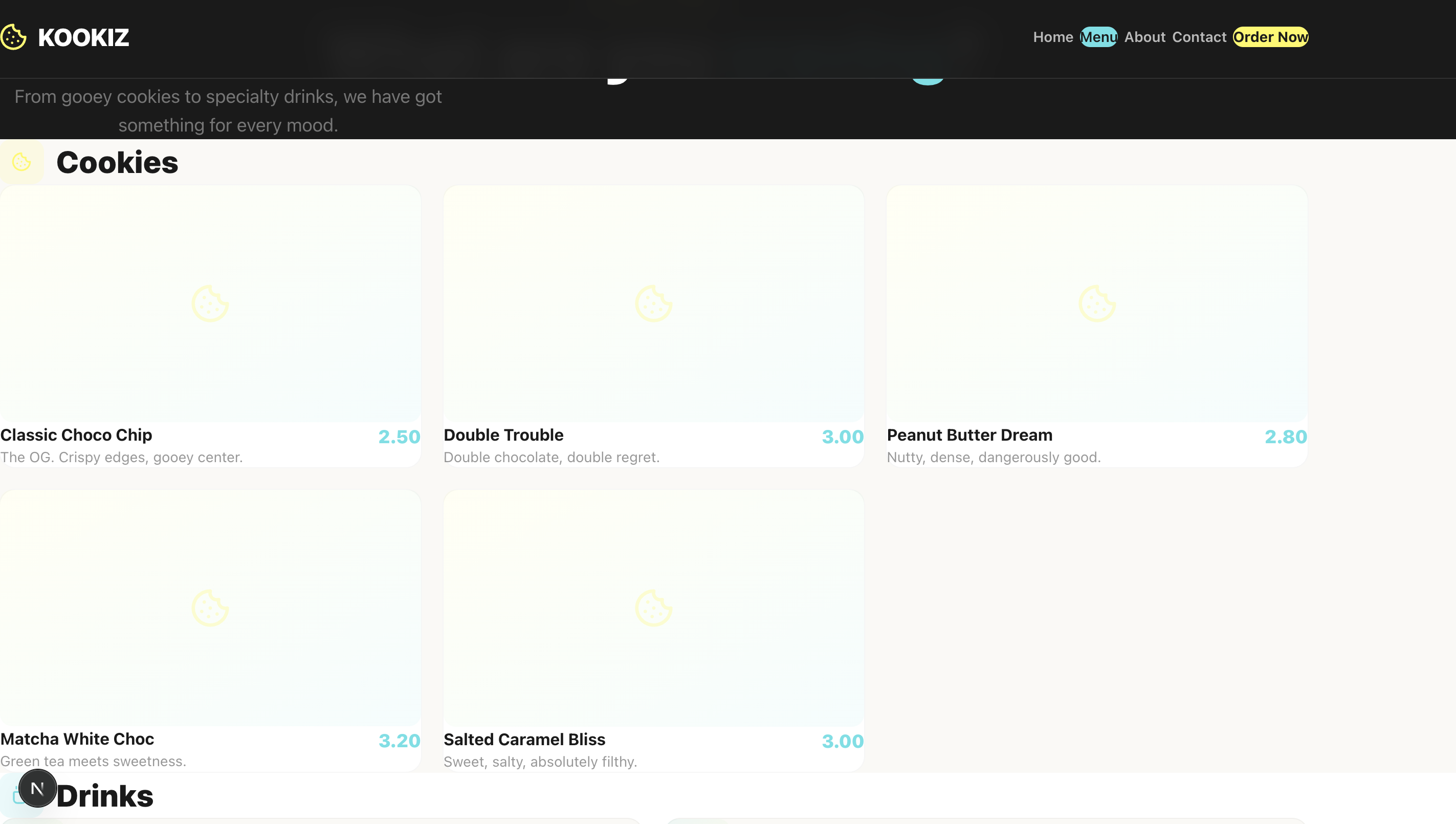
Seite: Menu (Abschnitt 1)
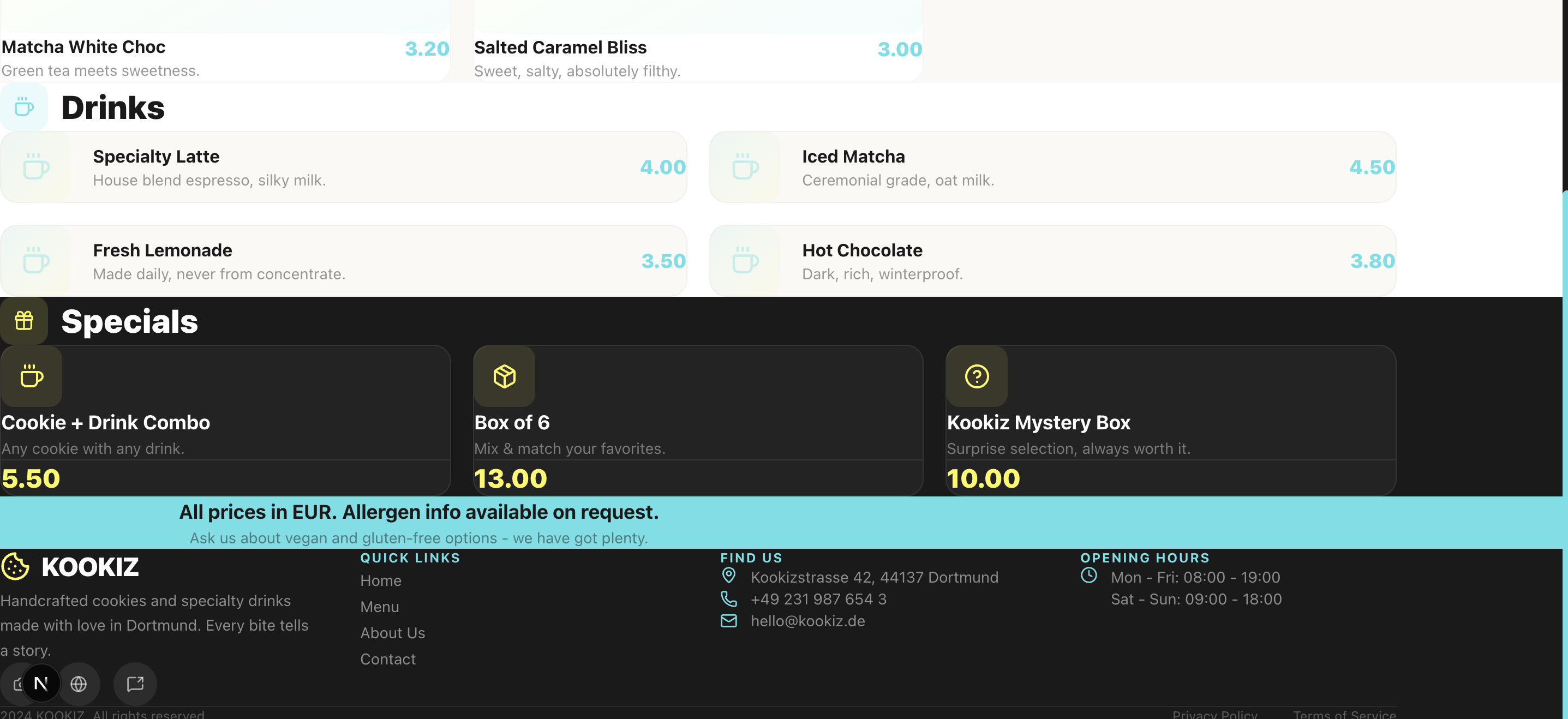
Seite: Menu (Abschnitt 2)
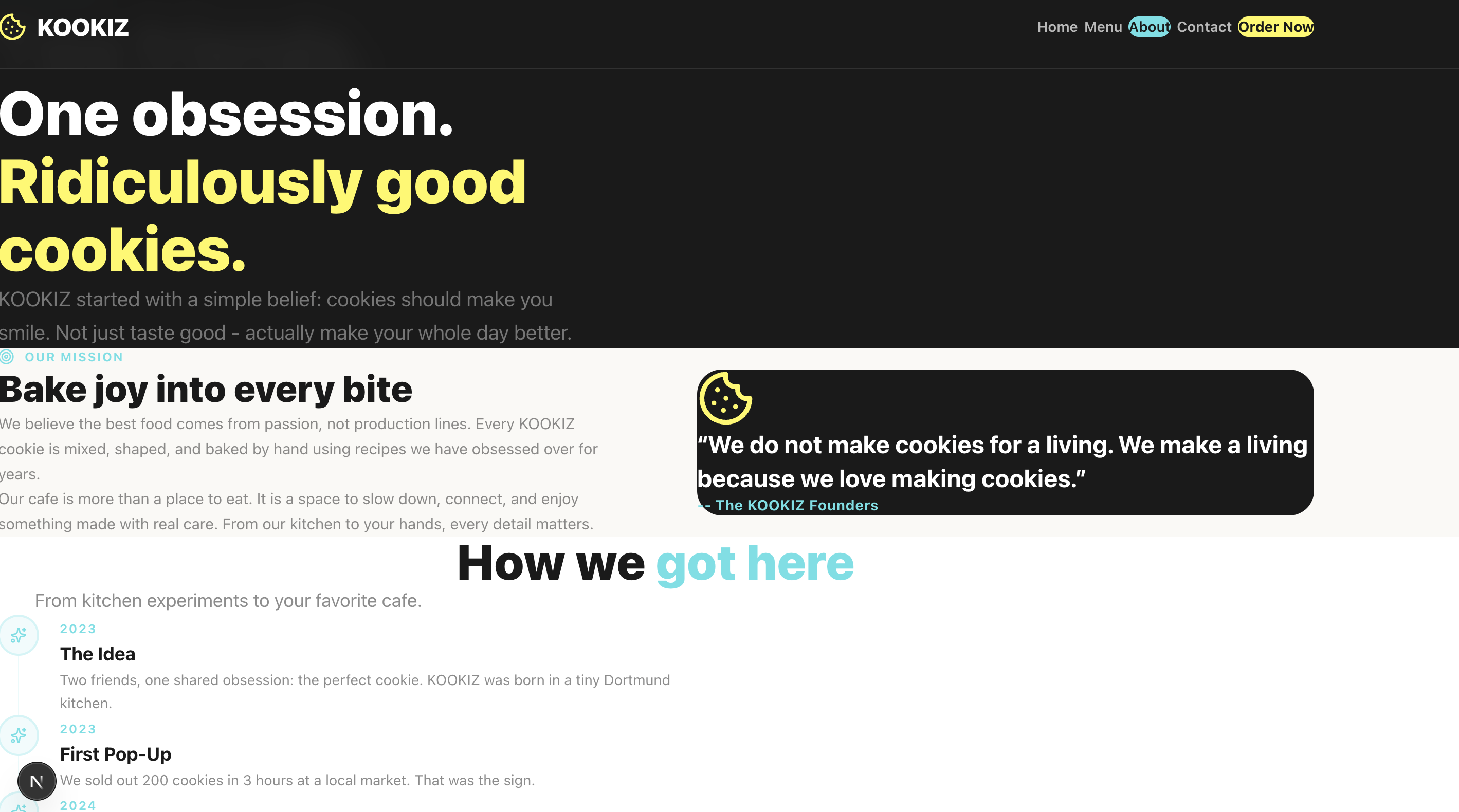
Seite: About
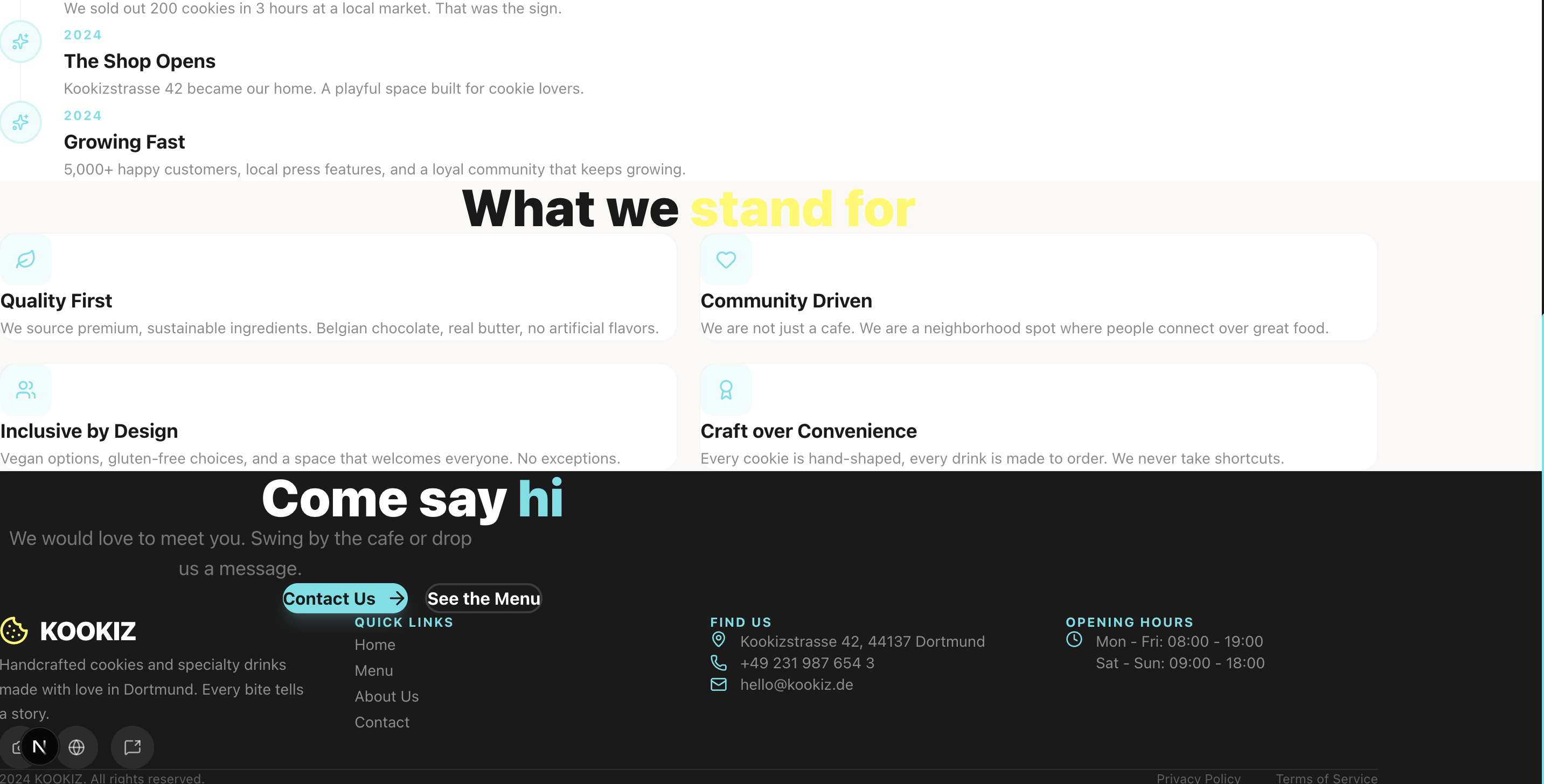
Seite: Contact
Du hast dir die Screenshots gerade angesehen und denkst vermutlich: "Was ist da passiert? Stimmt etwas mit den Bildern nicht?" Leider ist mit den Screenshots alles in bester Ordnung. Claude Opus 4.6 liefert in unserem Test ein schlichtweg unbrauchbares Ergebnis ab.
Abstände, Einrückungen, überlappende Container – alles ist ein wildes Durcheinander. Lediglich die Einhaltung unserer vorgegebenen Farbpalette und das strikte Emoji-Verbot wurden vom Modell respektiert. Claude hat zwar ambitioniert versucht, eine ausführliche About-Section zu kreieren, aber die Seite ist so schlichtweg nicht zu gebrauchen, da die Texte und Elemente wild ineinander übergehen und teilweise überlaufen.
Wie kann das sein? Immerhin gilt Claude Opus 4.6 doch als das mutmaßliche Topmodell am Markt! Wie bereits eingangs erwähnt, lässt dieses Ergebnis stark vermuten, dass die Einbettung des Modells in seinen eigenen proprietären Harness (wie bei Claude Code) mehr als nur einen geringen Einfluss auf das Endergebnis hat. In unserer neutralen Pi.Dev-Umgebung, in der das Modell ohne heimliche Hilfestellungen auskommen muss, fällt das rohe Coding-Ergebnis unerwartet chaotisch aus.
Viele werden sich nun fragen, ob es sich hier vielleicht nur um einen Ausrutscher gehandelt hat und man Claude nicht einfach noch einmal einen frischen Start geben sollte. Unsere klare Einschätzung lautet: Nein. Denn die Kosten für das misslungene Ergebnis sind real angefallen und werden uns schließlich auch nicht zurückerstattet.
Kostenpunkt: Gegen einen "zweiten Versuch" sprechen vor allem die extremen API-Kosten, die bei diesem desaströsen Versuch tatsächlich angefallen sind. Diese belaufen sich auf sagenhafte $3,51 – ein Vielfaches der Konkurrenz (GPT-5.5 lag bei $0,62, Gemini bei $0,35), und das für eine völlig unbrauchbare Website.
Lokale Open-Weight-Modelle: Der eigentliche Test
Nachdem die großen Cloud-Modelle stark (GPT-5.5, Gemini) bis katastrophal (Claude) vorgelegt haben, widmen wir uns nun dem eigentlichen Kern unseres Tests: Wie schlagen sich die lokalen Modelle?
Gemma 4 (26B-A4B, 8-bit AWQ)
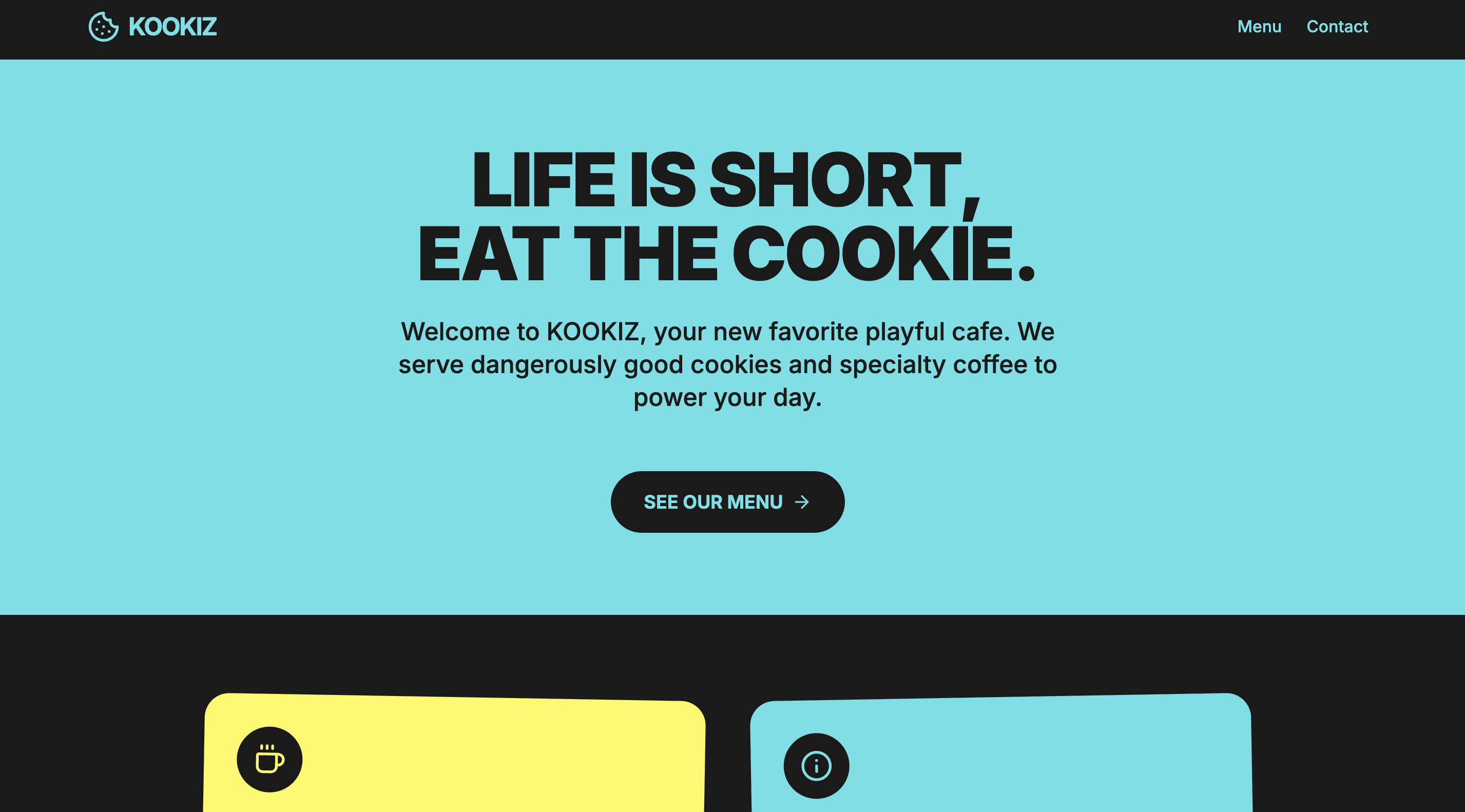
Seite: Landingpage (Abschnitt 1)

Seite: Landingpage (Abschnitt 2)
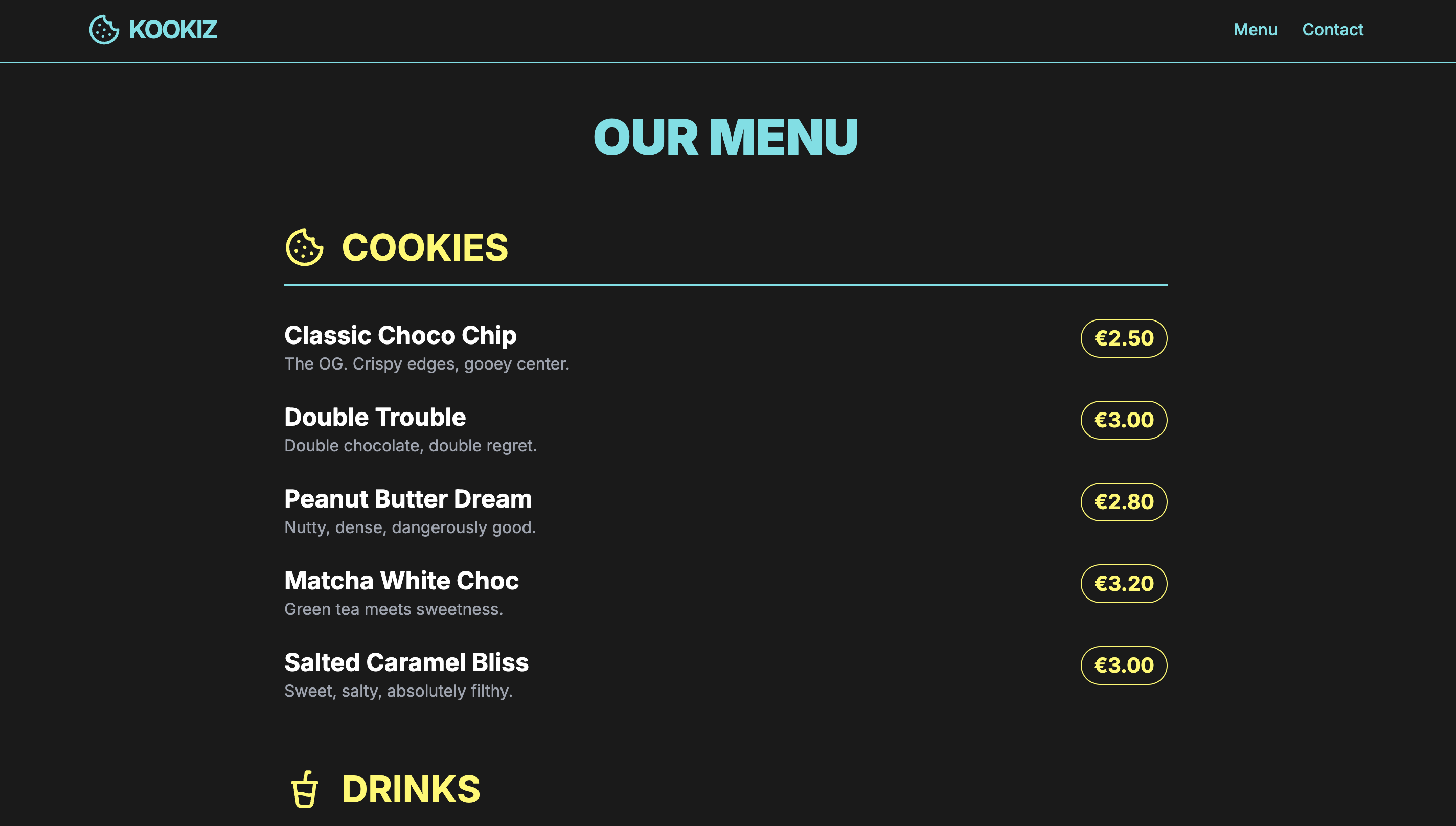
Seite: Menu (Abschnitt 1)
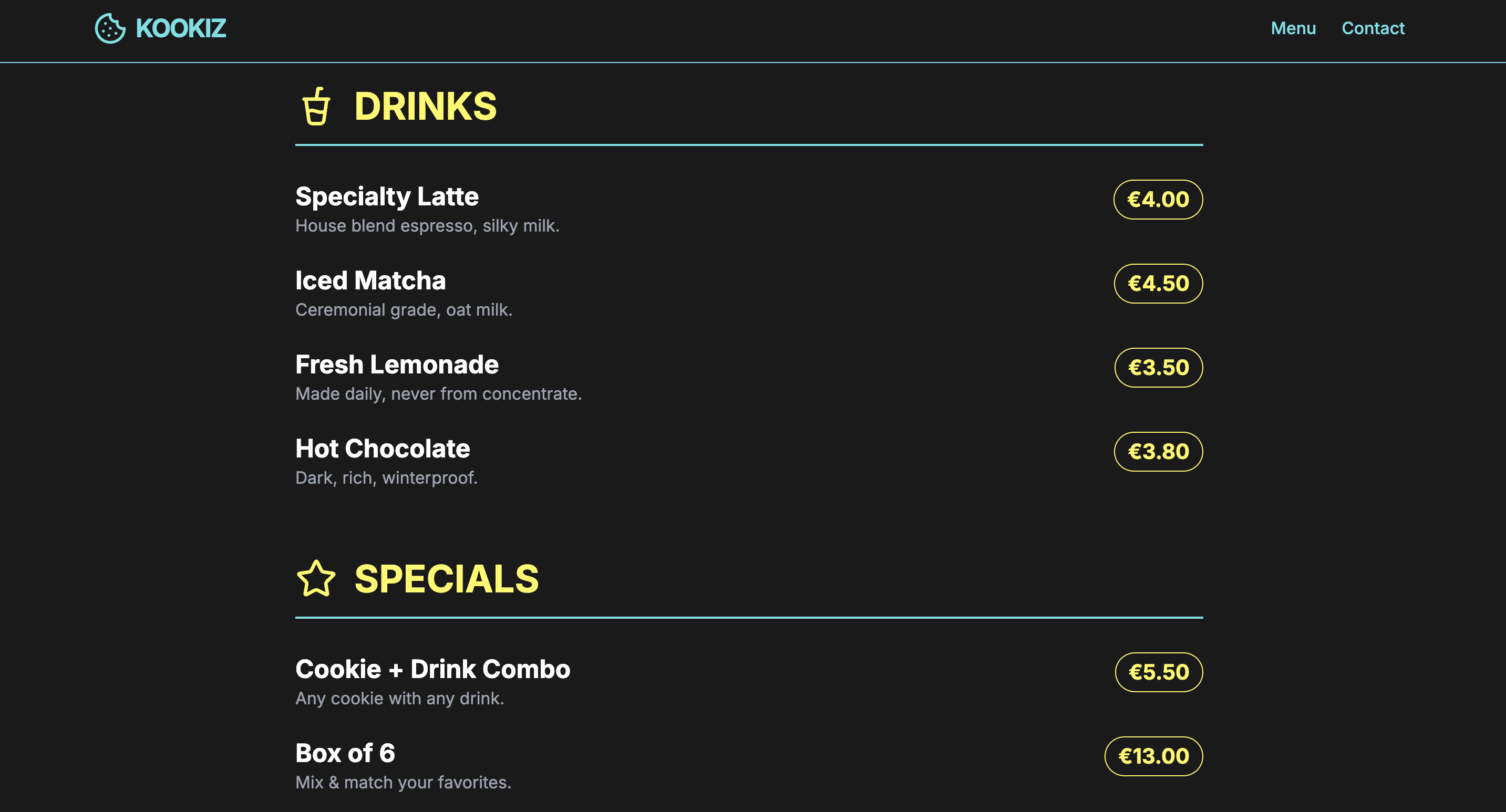
Seite: Menu (Abschnitt 2)

Seite: Contact
Beide von uns getesteten Gemma-Modelle spielen qualitativ grob in derselben Liga wie das Cloud-Modell Gemini 3.1-Pro-Preview.
Die 26B-Variante liefert eine durchweg brauchbare Website ab. Das Design wirkt "rund" und stimmig, hält sich aber stark zurück, wenn es um Verspieltheit oder kreative Ausreißer geht. Die generierten Inhalte und das Layout sind solide Basis-Arbeit – nicht besonders innovativ, eher als Basis geeignet. Wer hier bereit ist, mit ein paar zielgerichteten Follow-up-Prompts manuell nachzusteuern, darf am Ende ein durchaus ordentliches Endprodukt erwarten.
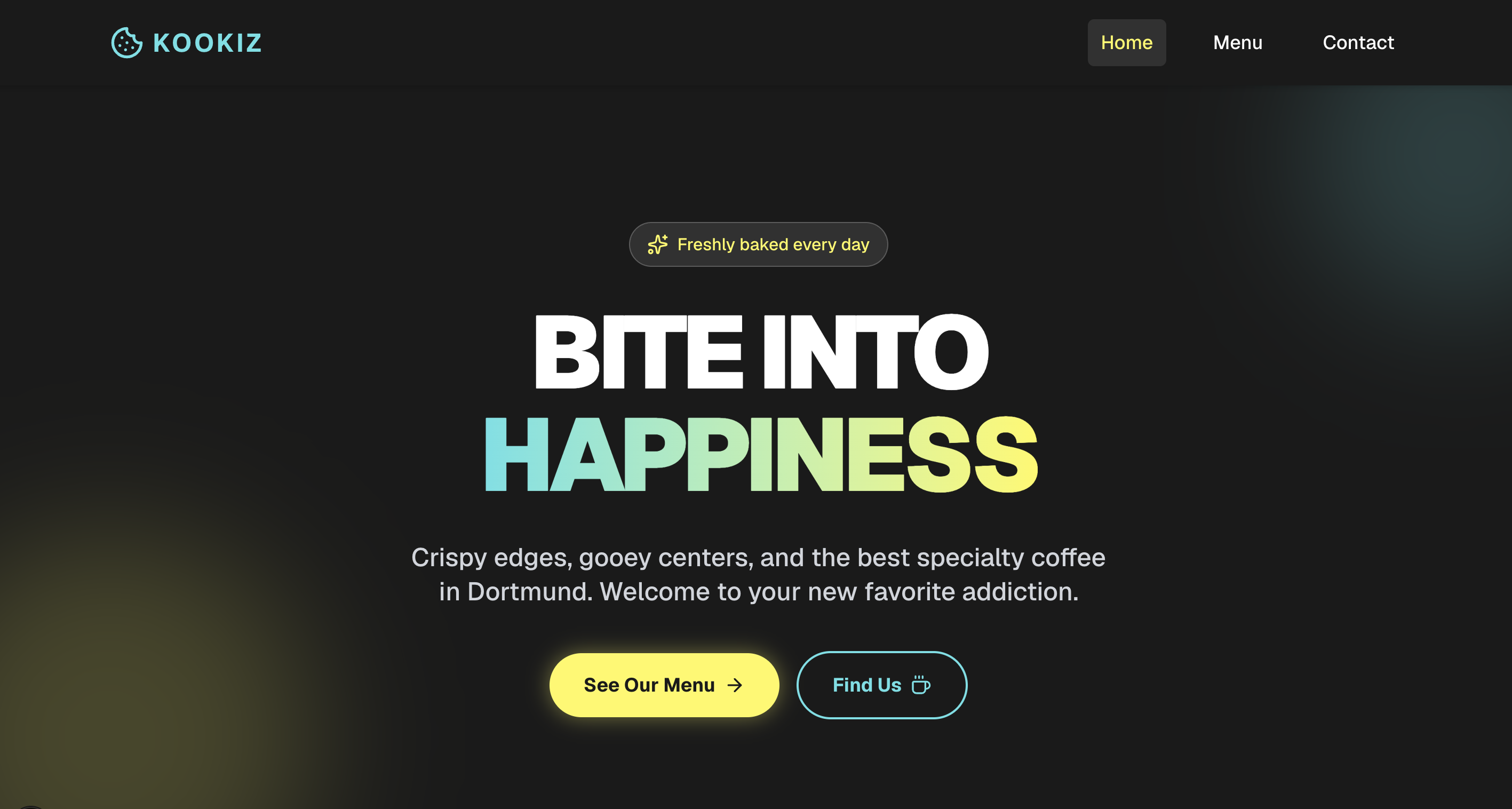
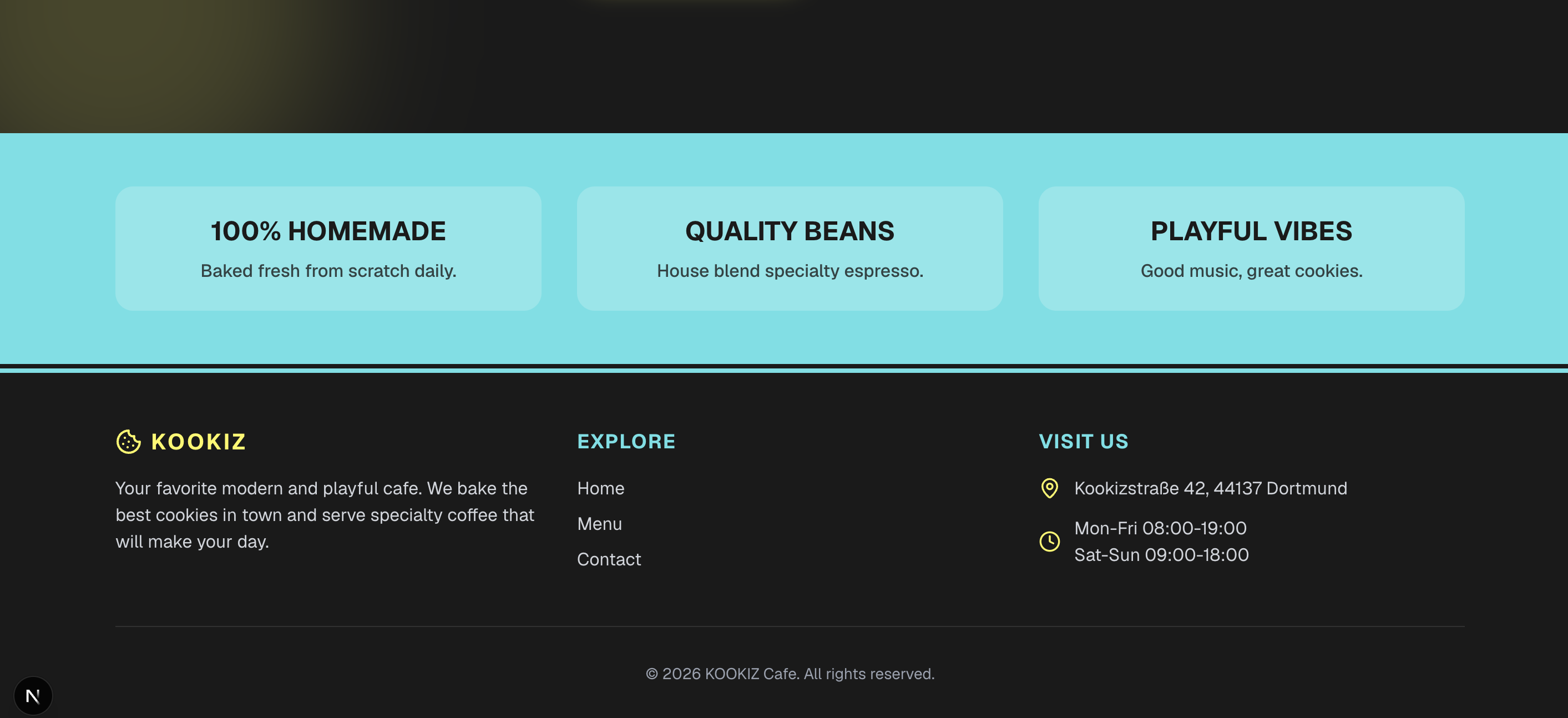
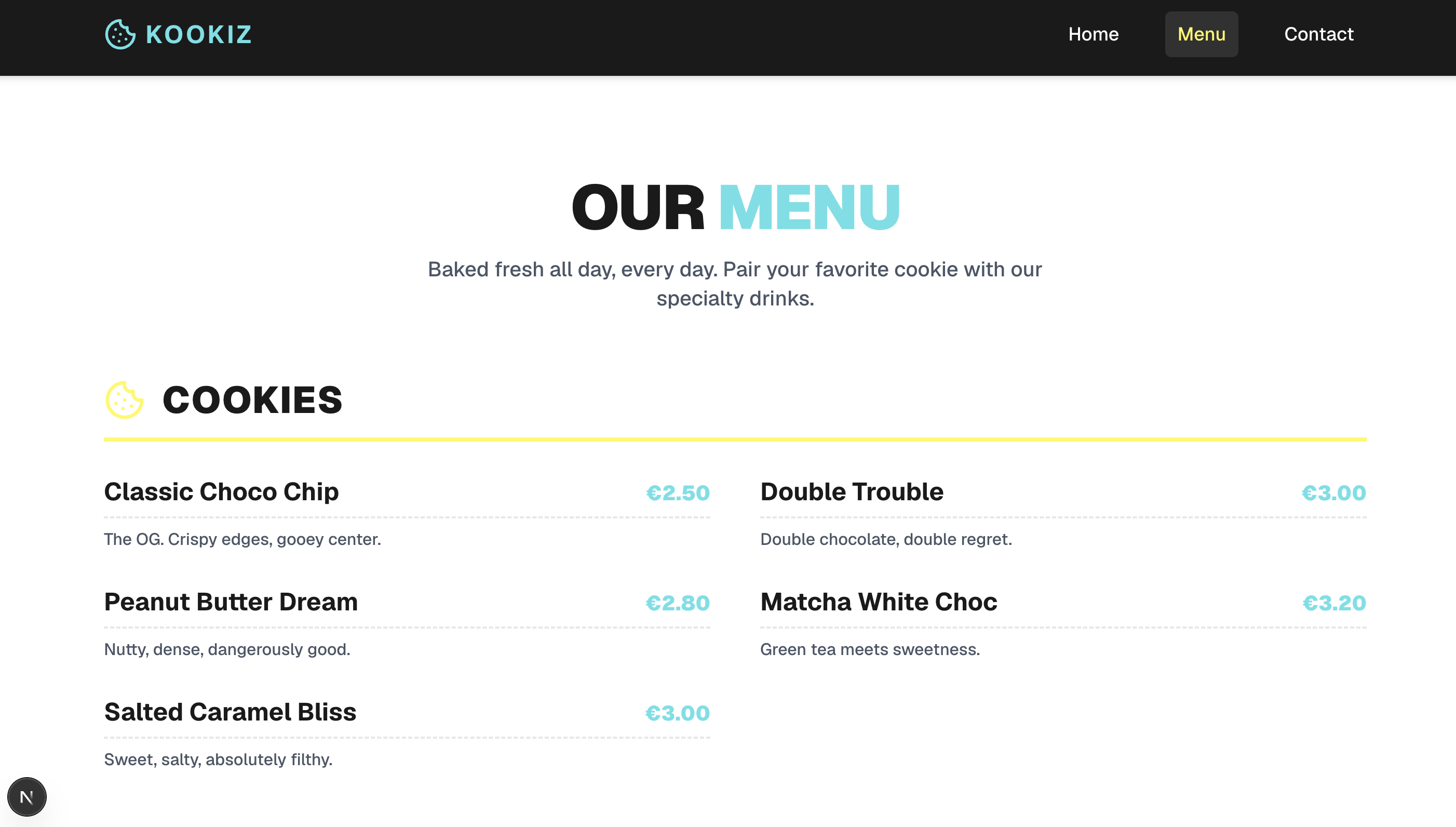
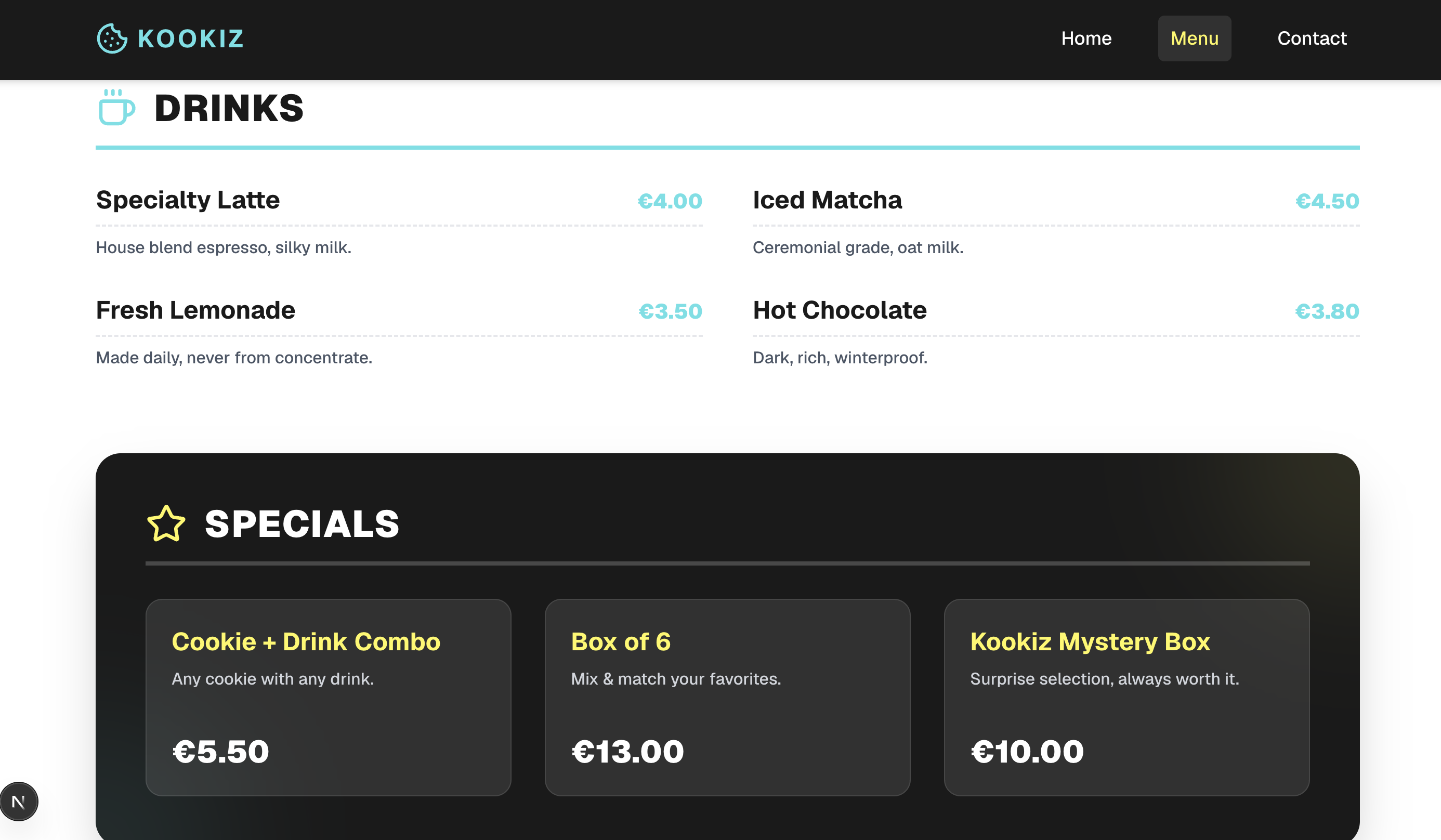
Gemma 4 (31B, 8-bit AWQ)
Seite: Landingpage (Abschnitt 1)
Seite: Landingpage (Abschnitt 2)
Seite: Menu (Abschnitt 1)
Seite: Menu (Abschnitt 2)
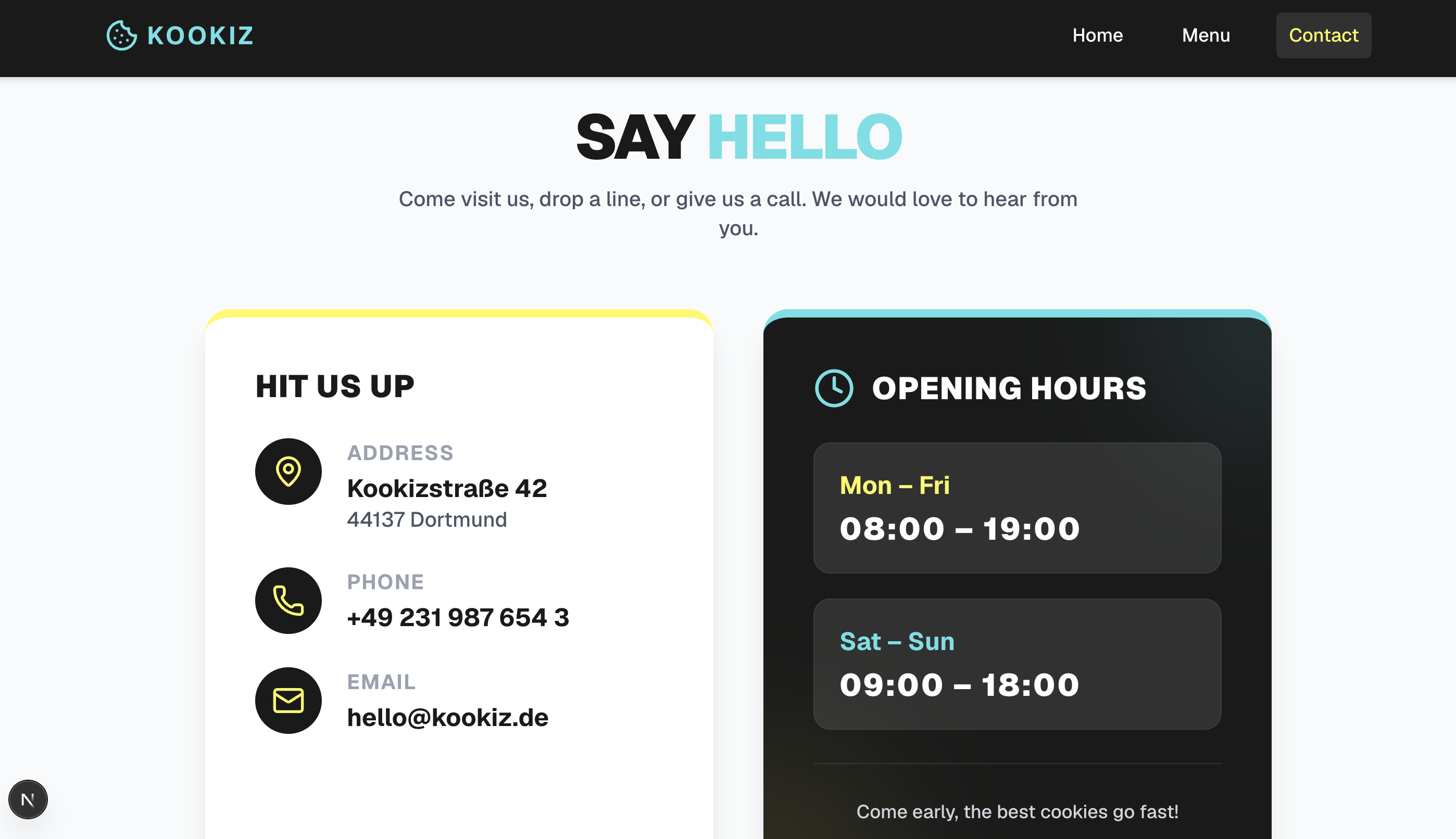
Seite: Contact
Das größere 31B-Modell setzt auf dem soliden Fundament der kleineren Version auf, liefert aber insgesamt ein spürbar besseres und detailreicheres Ergebnis.
Hier zeigt sich das größere Gemma-Modell deutlich mutiger: Die Hero-Section besticht durch boldere Schriftzüge, es kommen sanfte Farb-Gradienten zum Einsatz und der allgemeine Umgang mit UI-Elementen wirkt deutlich spielerischer. Obwohl es im Kern denselben funktionalen Ansatz wie die 26B-Version verfolgt, bemerkt man die zusätzlichen Parameter an der gesteigerten visuellen Tiefe und dem besseren Gespür für moderne Webdesign-Akzente. Es liegt qualitativ auf Augenhöhe mit dem Ergebnis von Gemini.
Qwen 3.6 (27B, 4-bit AWQ)
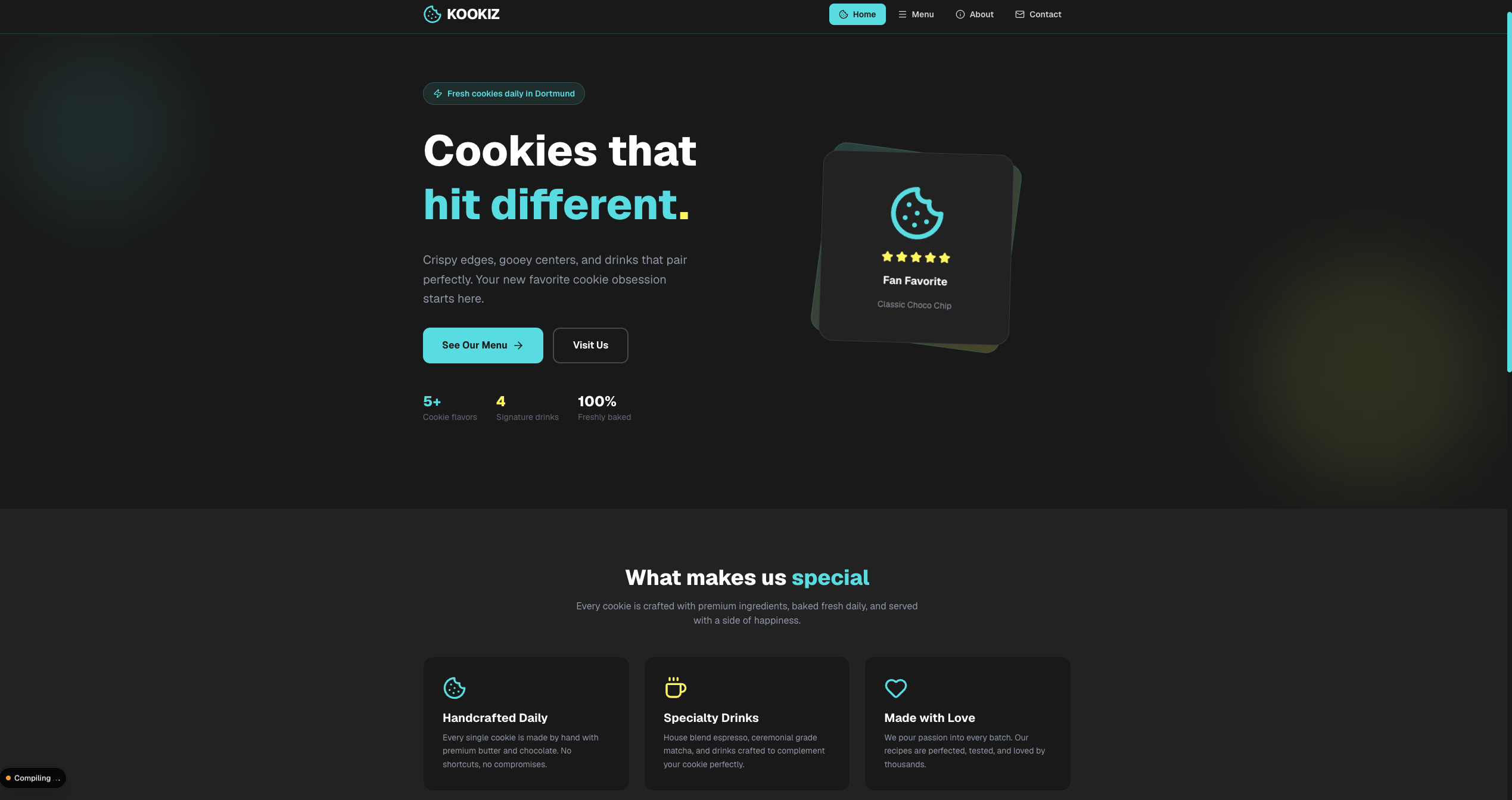
Seite: Landingpage (Abschnitt 1)
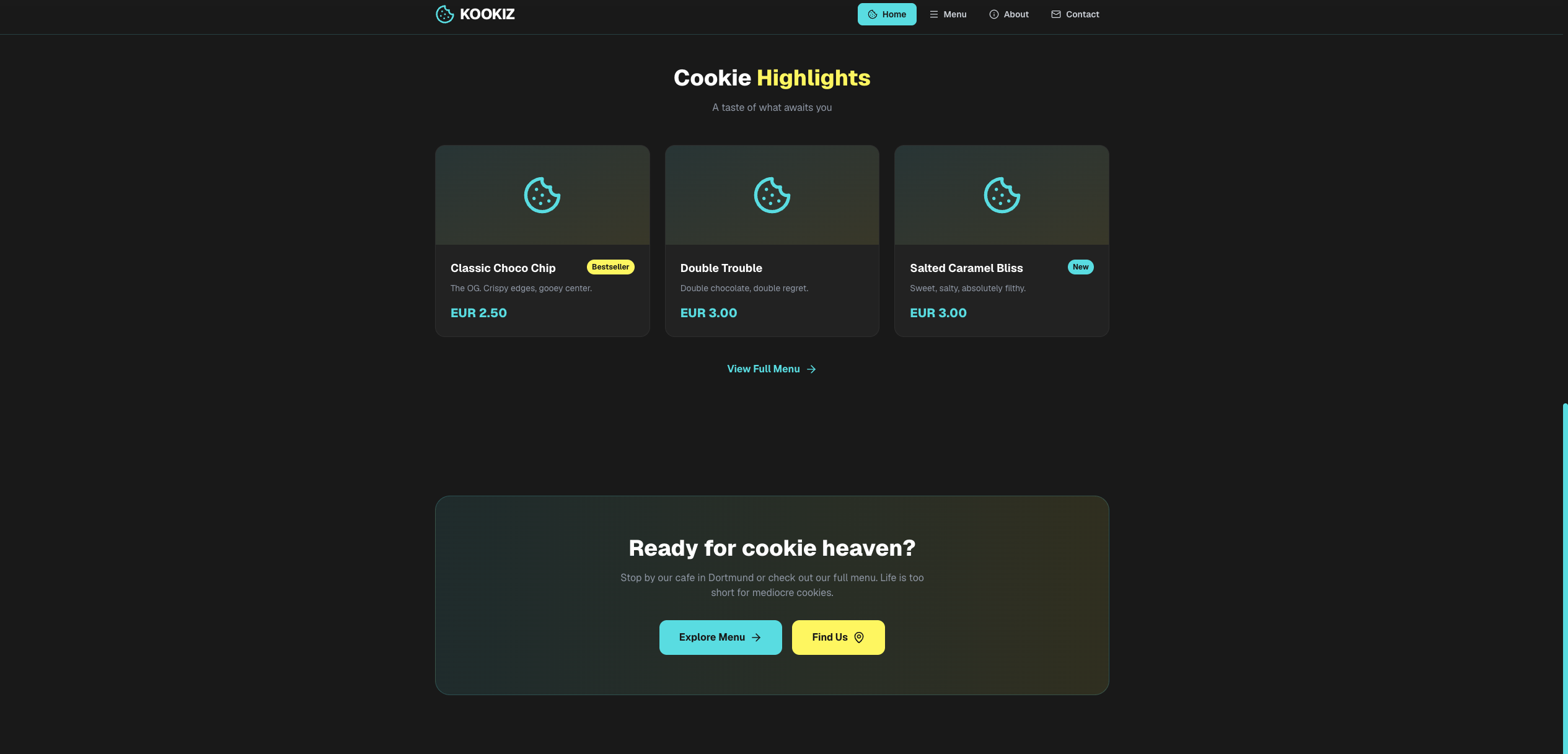
Seite: Landingpage (Abschnitt 2)
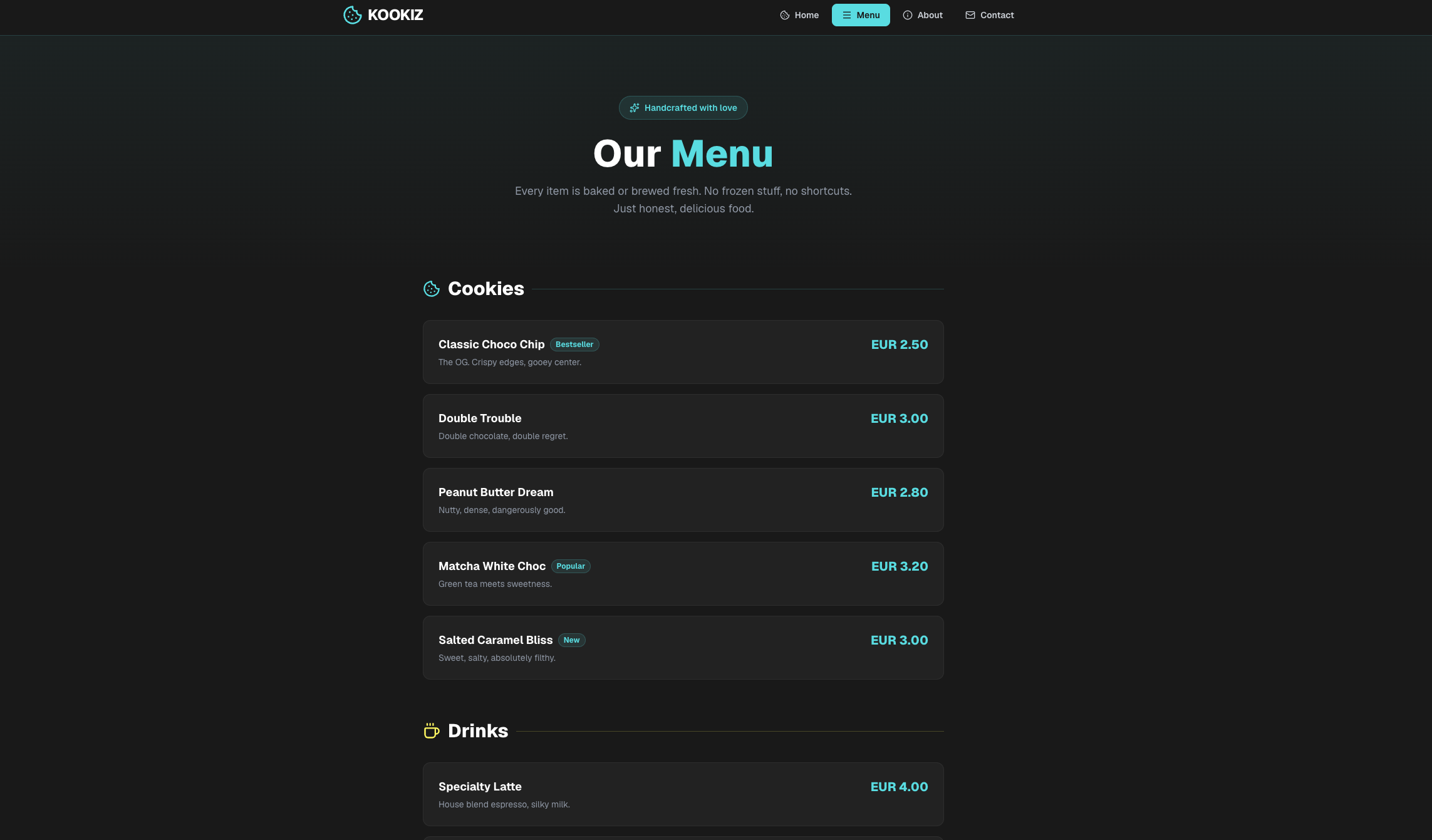
Seite: Menu (Abschnitt 1)
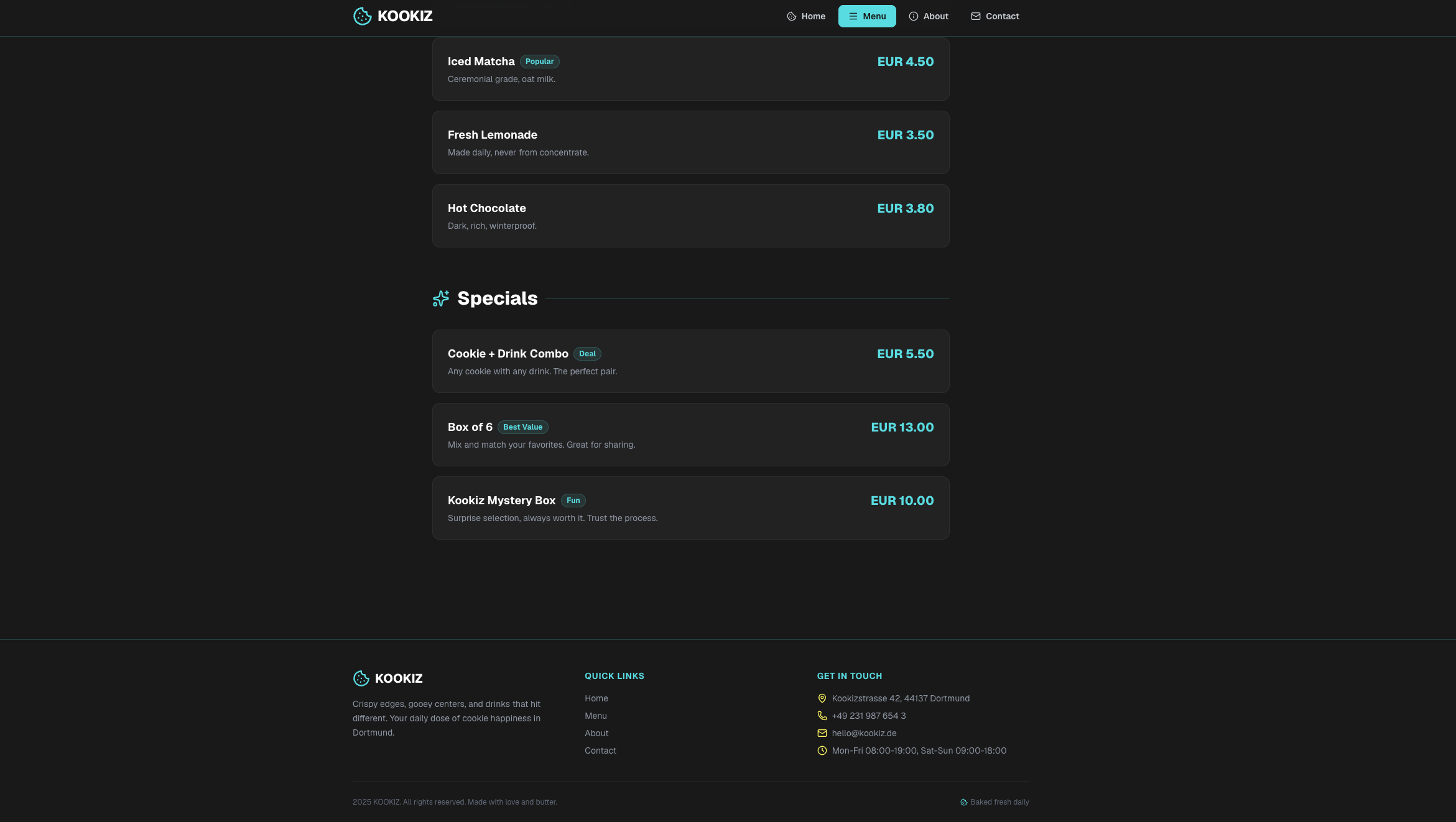
Seite: Menu (Abschnitt 2)

Seite: About (Abschnitt 1)
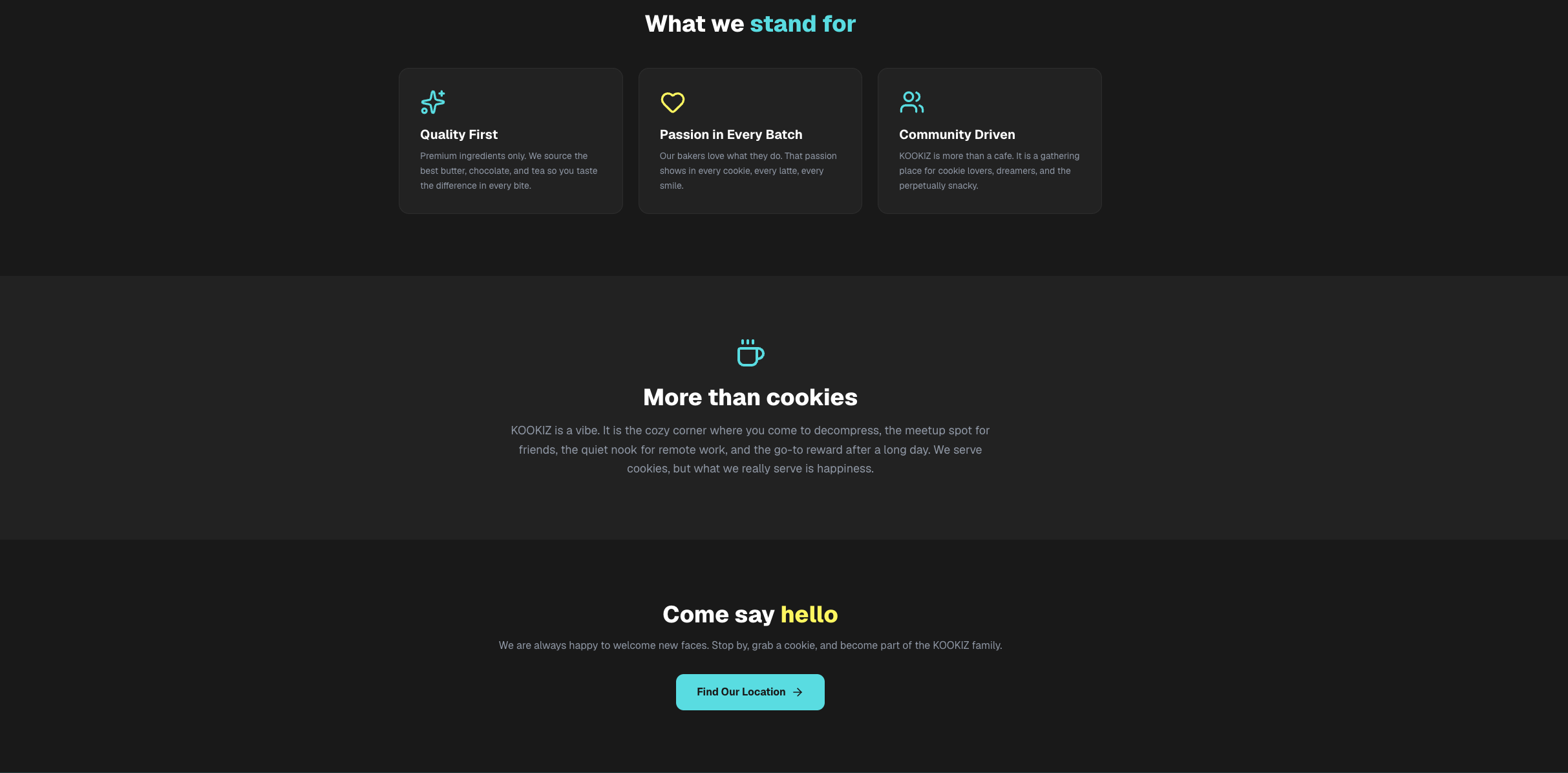
Seite: About (Abschnitt 2)
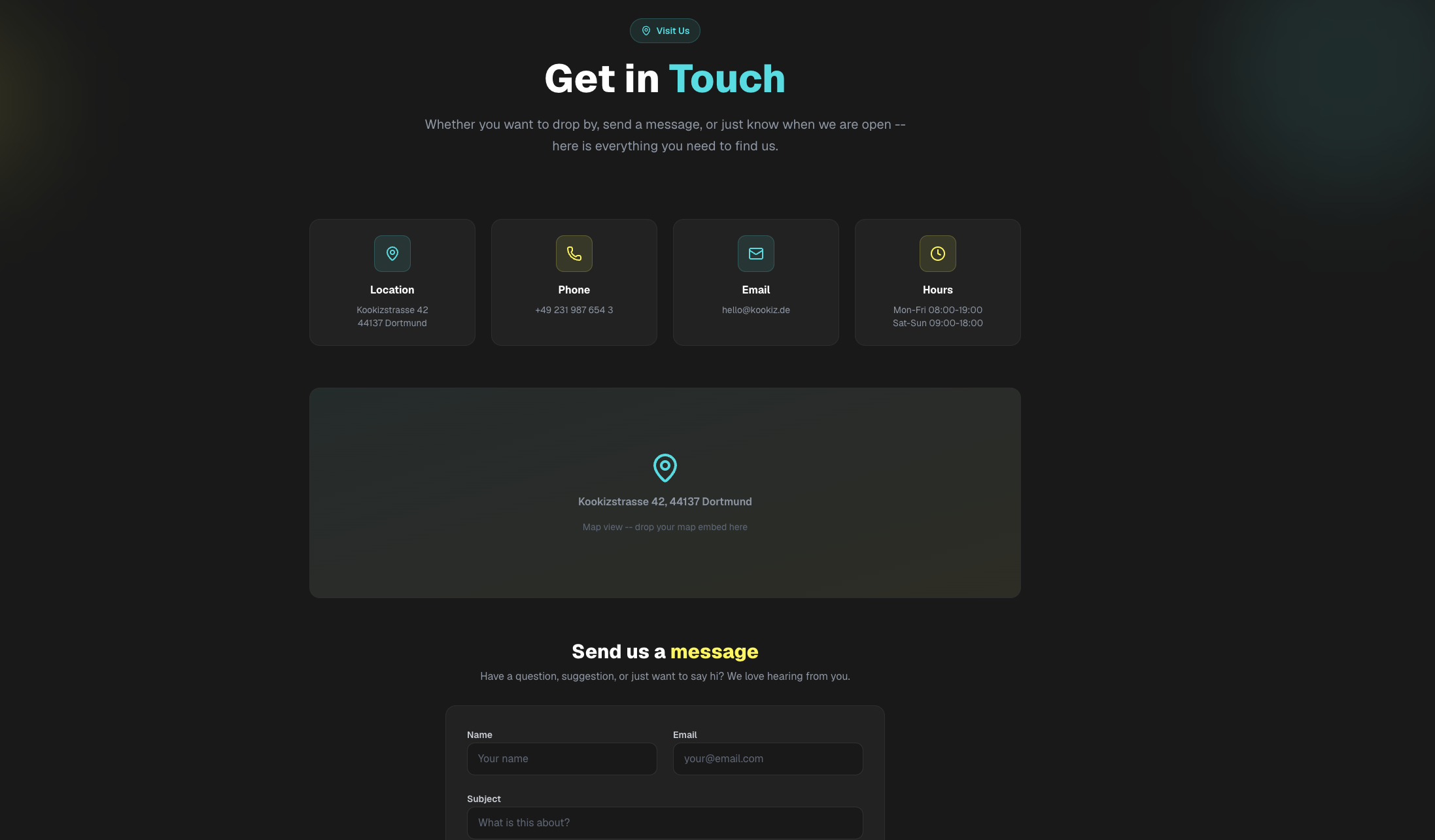
Seite: Contact (Abschnitt 1)
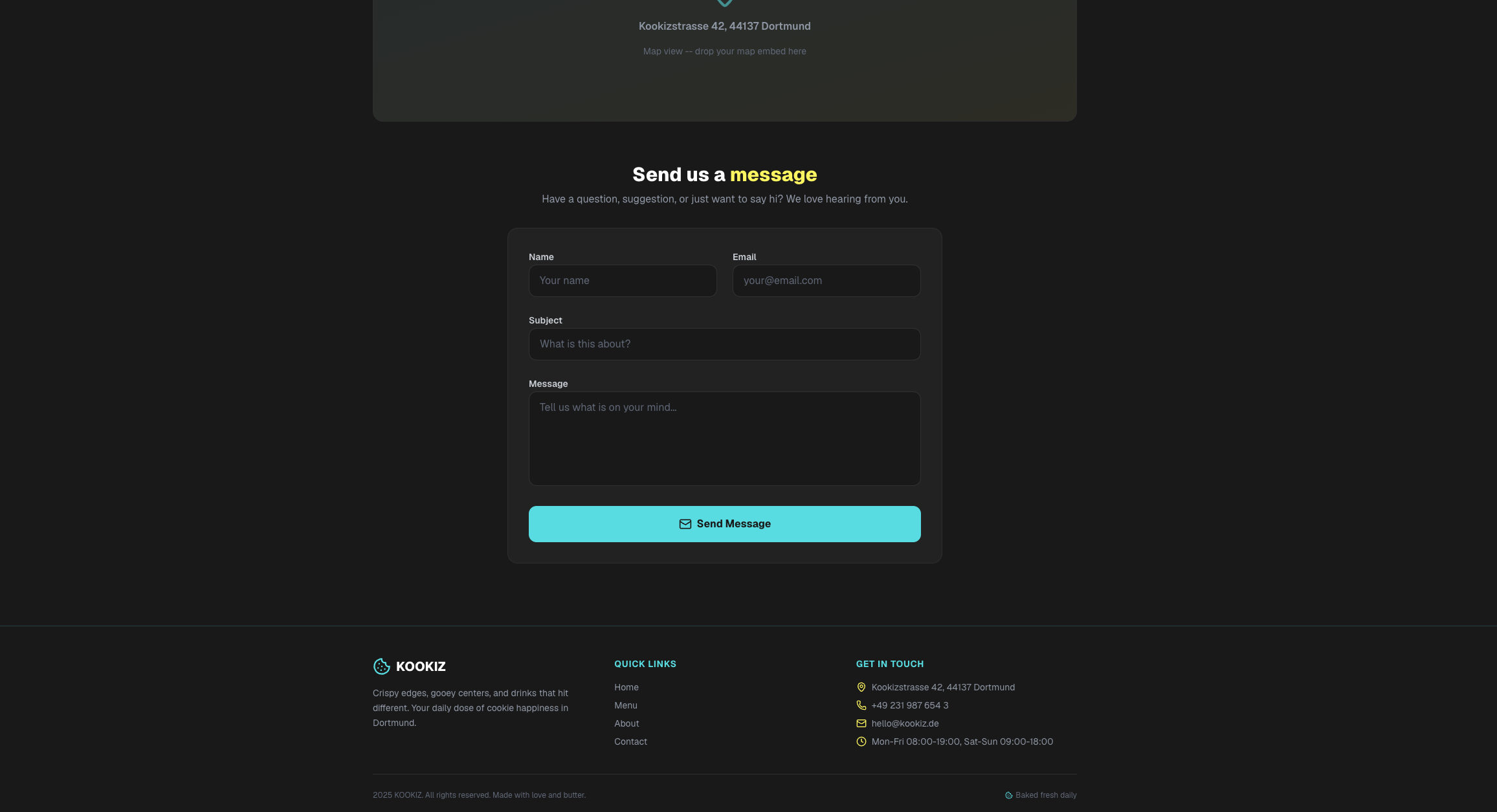
Seite: Contact (Abschnitt 2)
Insgesamt lassen sich die Ergebnisse der Qwen-Modelle deutlich stärker einschätzen als die von Gemma 4.
Hier sticht vor allem das Qwen 27B-Modell heraus: Es glänzt mit einem hohen Detailgrad und bemerkenswerter Präzision bei der Umsetzung. Tatsächlich stufen wir dieses Ergebnis sogar höher ein als das des kostenpflichtigen Gemini 3.1-Pro-Preview. Ein entscheidender Faktor dafür ist die ausführlich gefüllte About-Section, die bei Gemini schlichtweg völlig fehlte. Selbstverständlich wurden auch hier alle formalen Vorgaben – von der Einhaltung unserer Corporate Colors bis hin zum strengen Emoji-Verbot – exzellent umgesetzt.
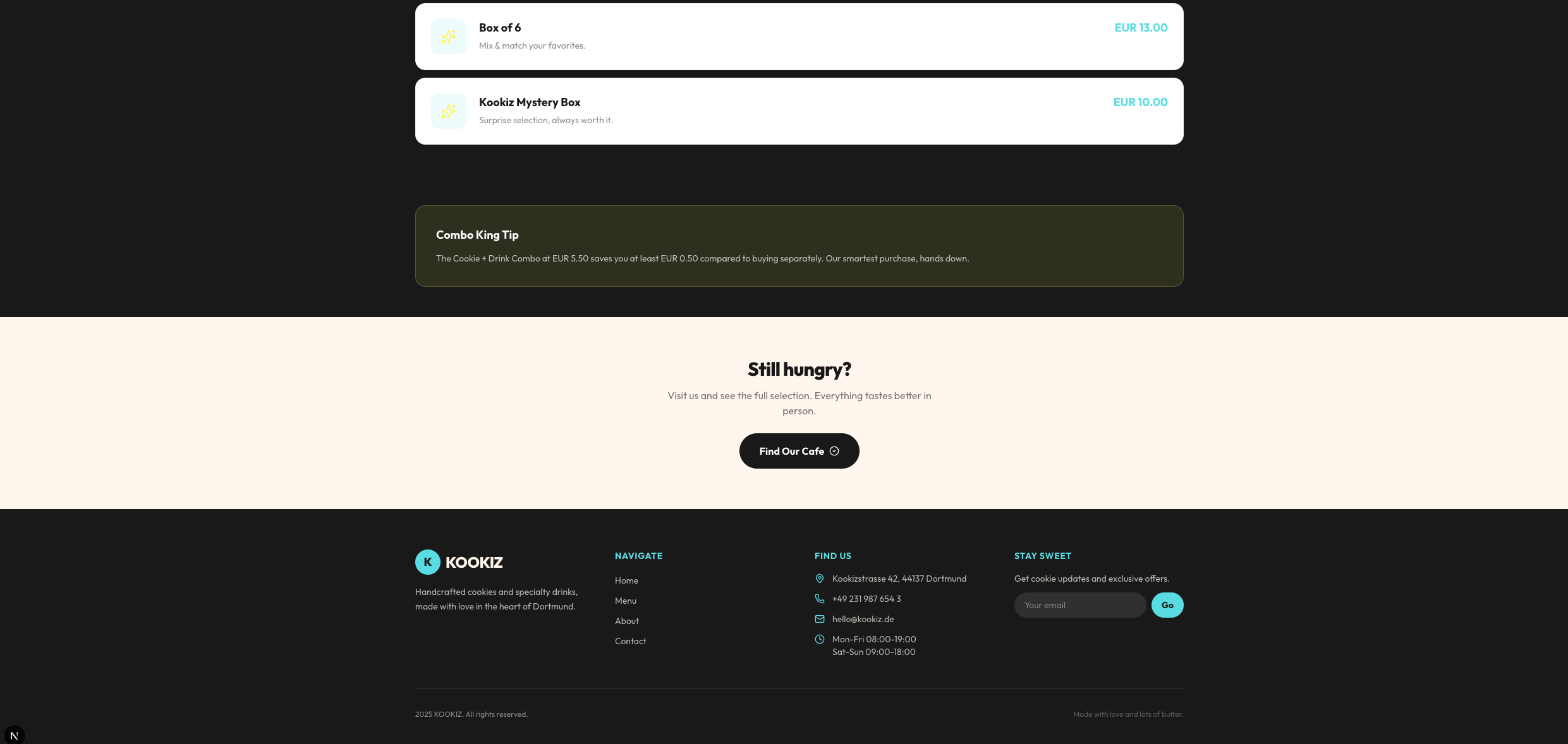
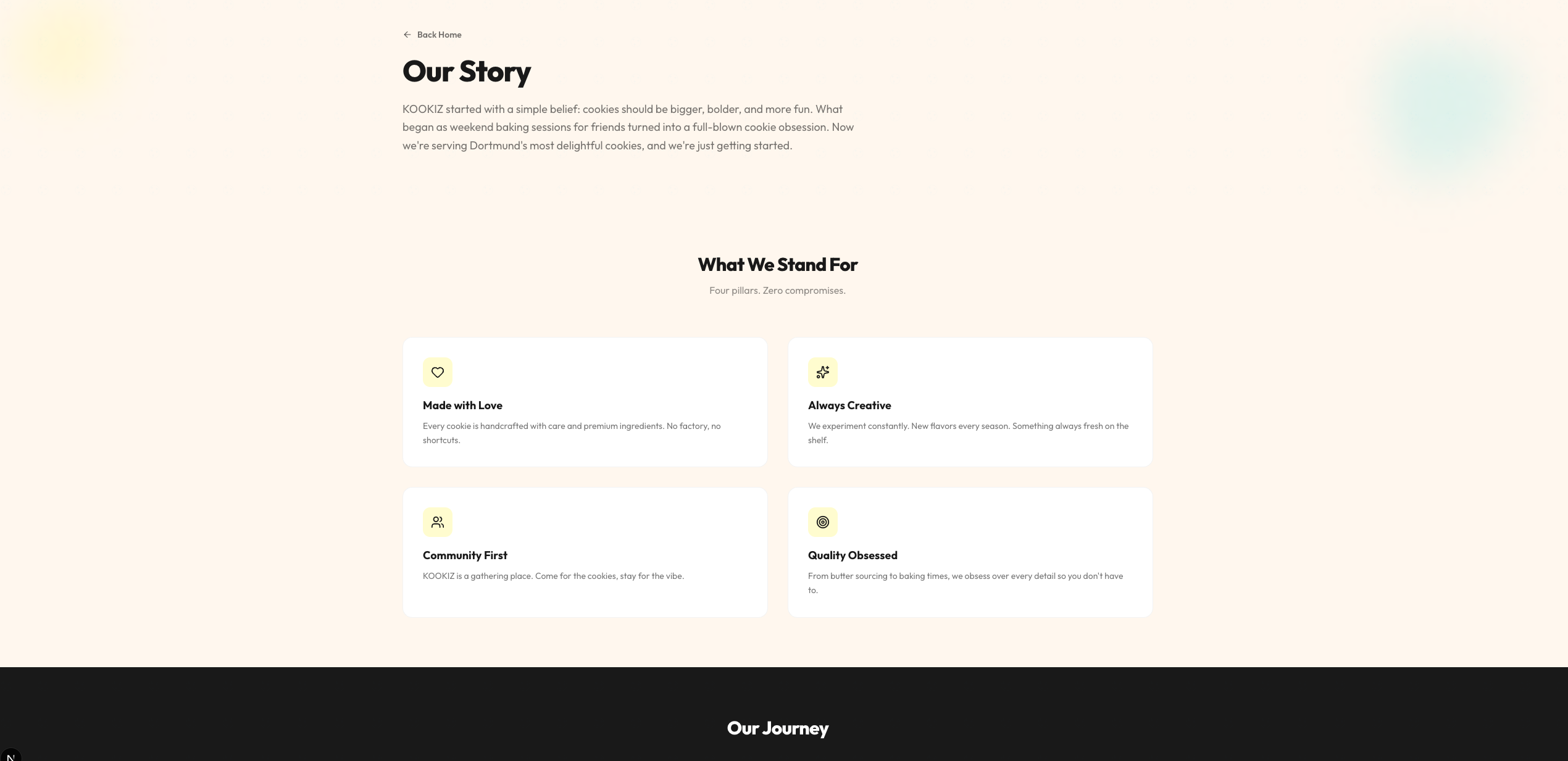
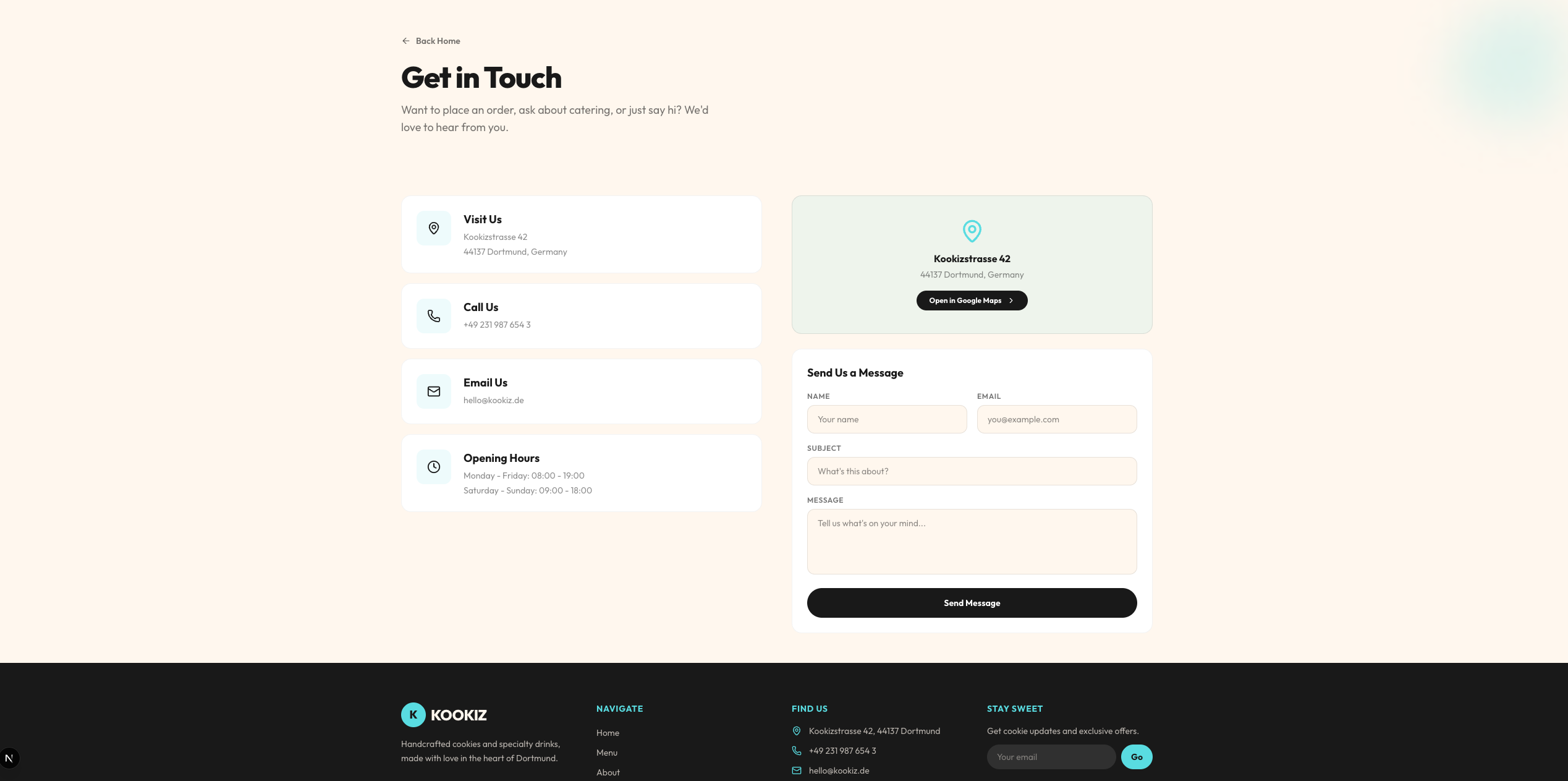
Qwen 3.6 (35B-A3B, 4-bit AWQ)
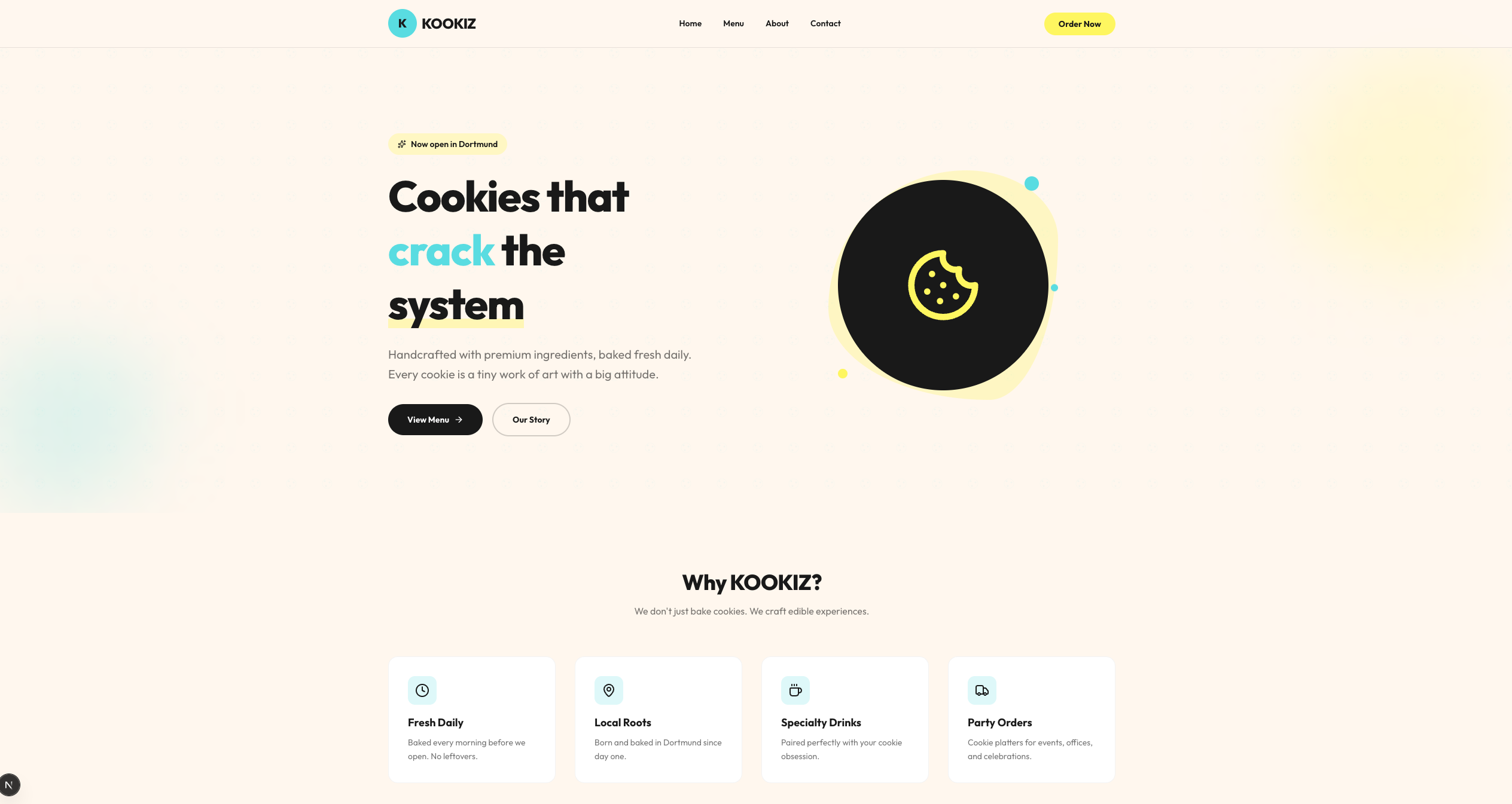
Seite: Landingpage (Abschnitt 1)
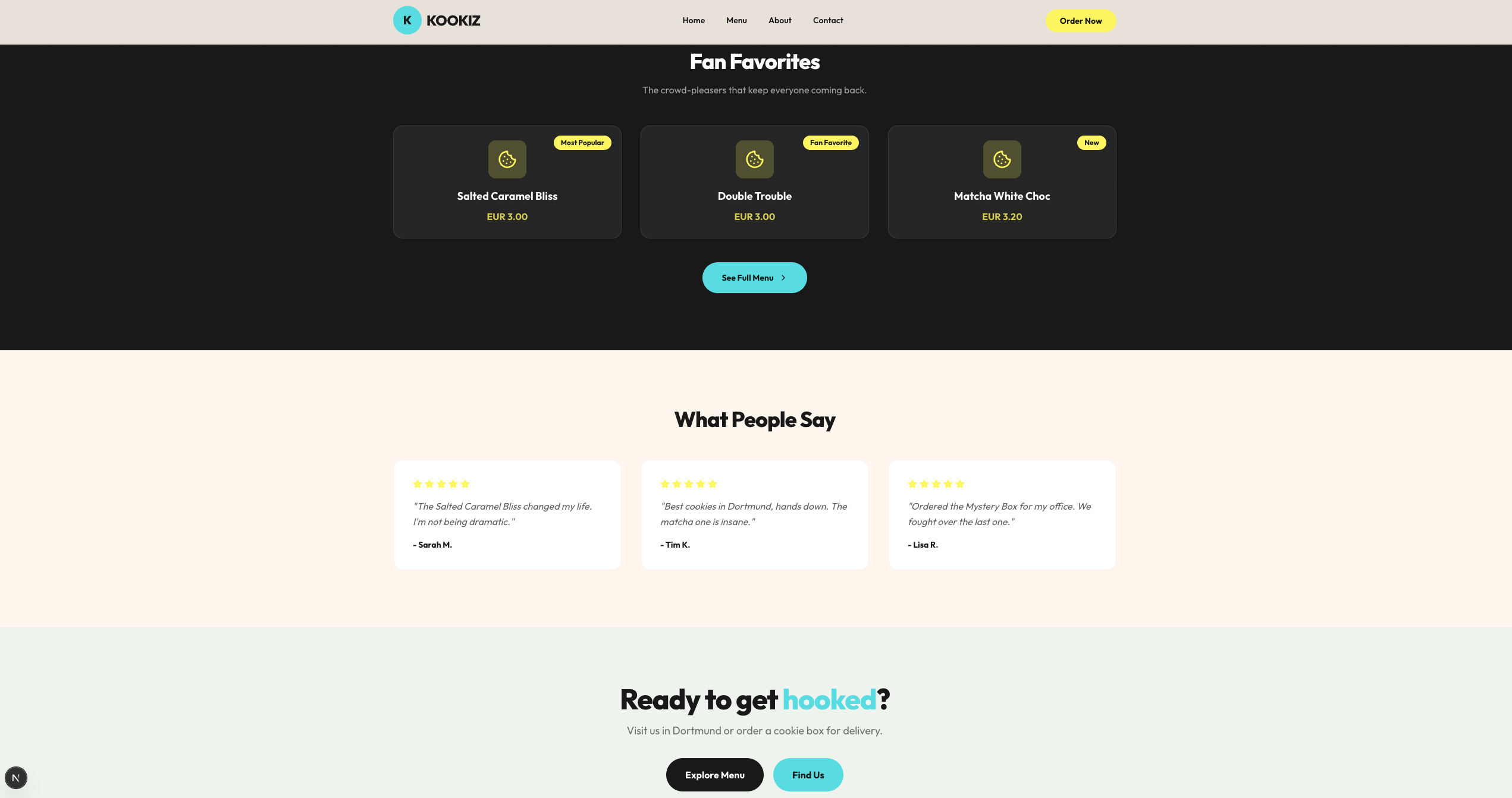
Seite: Landingpage (Abschnitt 2)
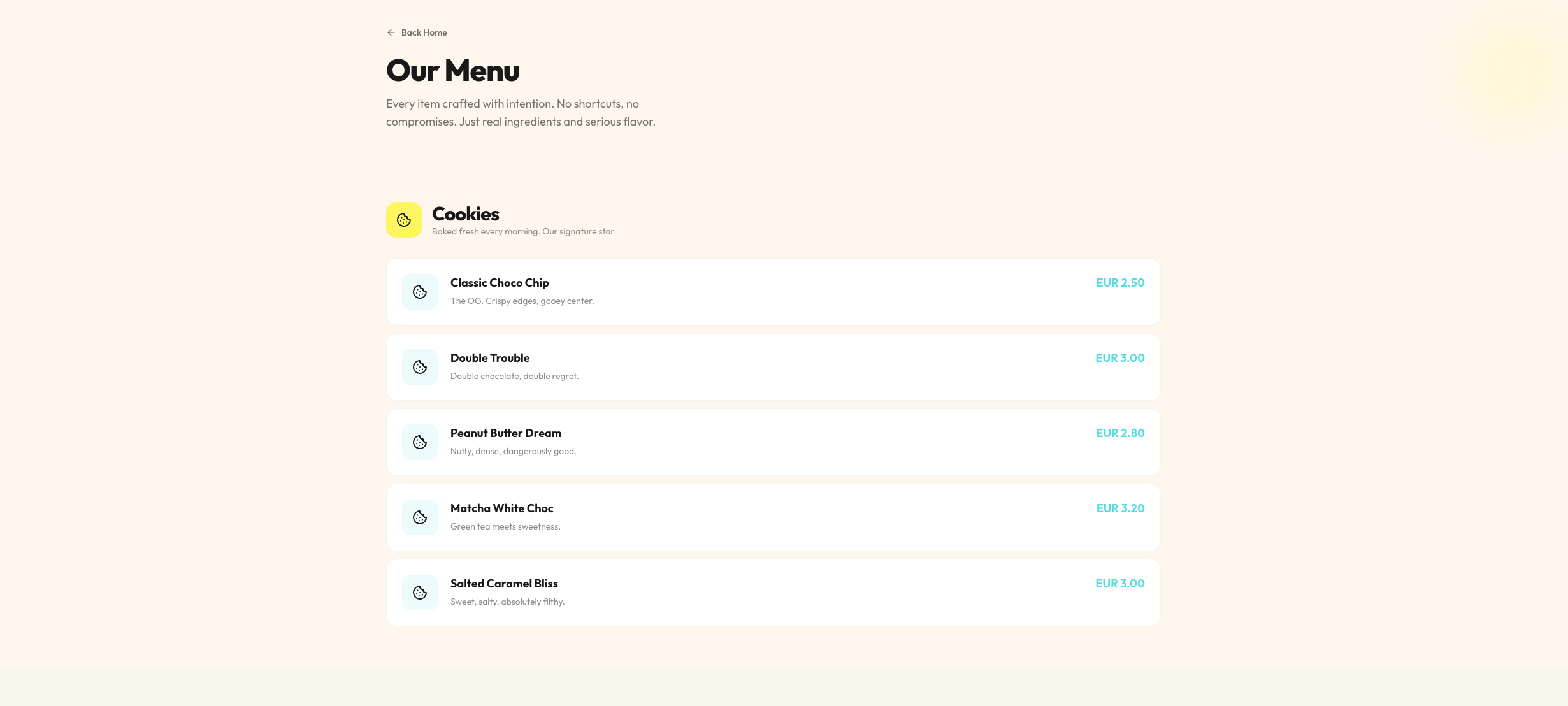
Seite: Menu (Abschnitt 1)
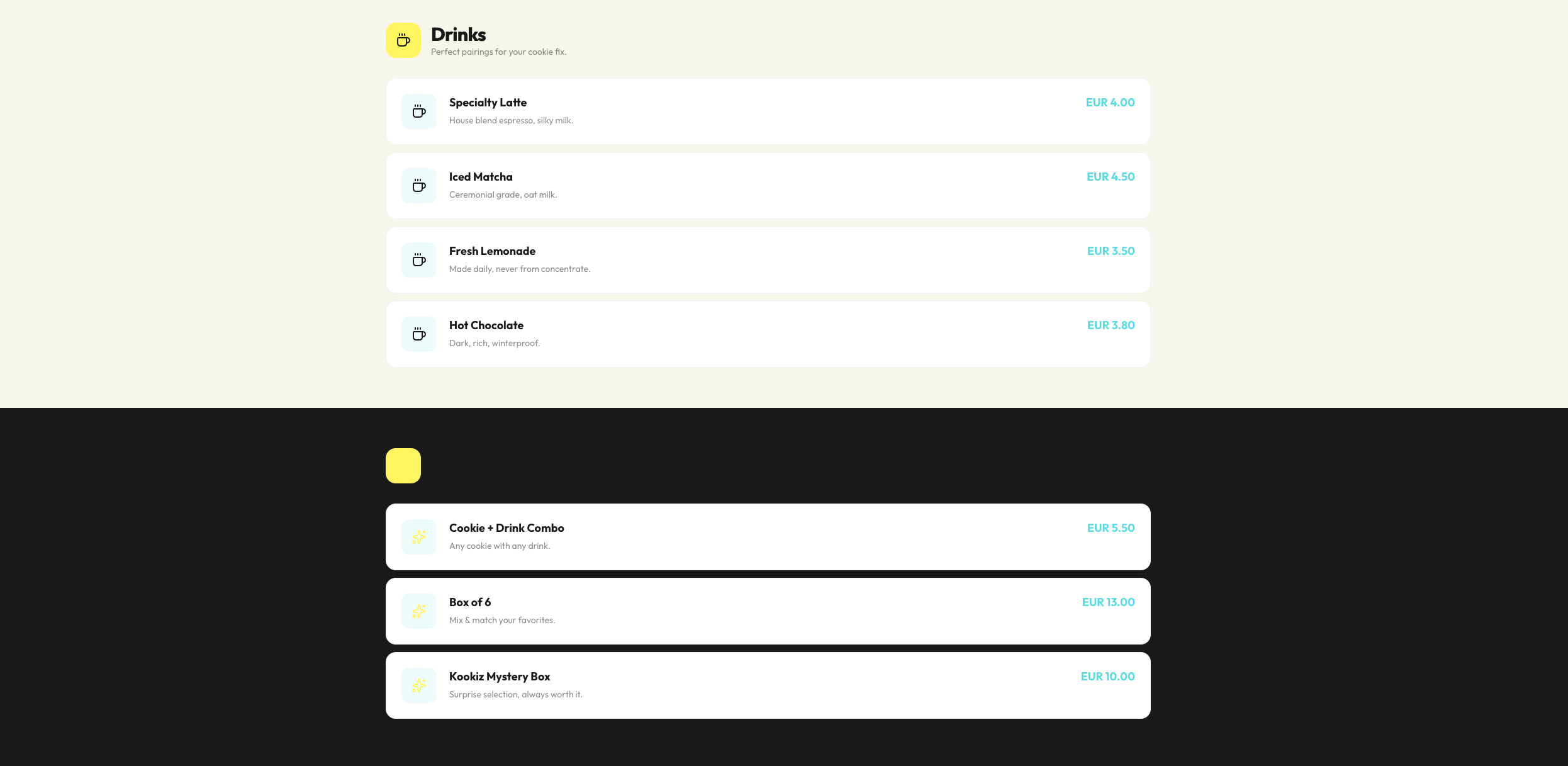
Seite: Menu (Abschnitt 2)
Seite: Menu (Abschnitt 3)
Seite: About (Abschnitt 1)

Seite: About (Abschnitt 2)
Seite: Contact
Das größere Qwen 35B-Modell liefert zwar einen vergleichbaren Detailgrad wie sein kleinerer Bruder (inklusive einer ausgedehnten Menü- und About-Sektion), das visuelle Ergebnis ist jedoch deutlich weniger ansprechend.
Hier offenbaren sich Schwächen im Design-Verständnis: Die vorgegebenen Farben wurden teilweise nicht sinnvoll kombiniert. So finden sich häufig helle Texte auf noch helleren Hintergrund-Elementen wieder, was sie fast unsichtbar macht. Trotz dieser optischen Mängel ist aber auch dieses Ergebnis als solide strukturelle Grundlage absolut brauchbar. Genau wie bei Gemma gilt auch hier: Mit ein paar wenigen gezielten Folgeprompts zur Kontrast-Anpassung ließe sich daraus schnell etwas sehr Ordentliches zaubern.
Abschlussbetrachtung & Geschwindigkeit
Ein kurzes Wort zur Performance: Wie zu erwarten war, haben die MoE-Modelle (Mixture of Experts) bei der Tokengenerierung einen Geschwindigkeitsvorteil gegenüber den klassischen Dense-Modellen. Insgesamt bewegen sich die lokalen Modelle bei der Tokengenerierung jedoch durchweg bei etwa 40-50 Tokens pro Sekunde – ein Niveau, das dem der Cloud-Anbieter in nichts nachsteht. Es gab im Test keinen so signifikanten Geschwindigkeitsunterschied, der als alleiniges Kriterium den Ausschlag für oder gegen ein bestimmtes Modell geben würde. Am Ende entscheidet also primär die qualitative Output-Leistung.
Das finale Ranking
Um die Ergebnisse übersichtlich zusammenzufassen, haben wir die getesteten Modelle in zwei Kategorien gerankt: Design (Wie modern, stimmig und optisch ansprechend sah das Layout aus?) und Detailgrad (Wie tiefgreifend wurden Inhalte generiert und Sektionen wie z.B. "About" ausgearbeitet?).
Ranking: Design & Ästhetik
- GPT-5.5 (OpenAI / Cloud) – Überragendes Design, sehr verspielt ("Wow"-Faktor).
- Qwen 3.6 27B (Lokal / Dense) – Design zweckmäßig, aber stimmig; Fokus lag primär auf Inhalt.
- Gemini 3.1-Pro-Preview (Google / Cloud) – Sehr sauber, aber konservatives Basic-Layout.
- Gemma 4 31B (Lokal / Dense) – Etwas mutiger als 26B, sanfte Gradienten.
- Gemma 4 26B (Lokal / Dense) – Solides, rundes Basic-Design.
- Qwen 3.6 35B-A3B (Lokal / MoE) – Abzüge wegen teilweise unlesbarer Farbkombinationen.
- Claude Opus 4.6 (Anthropic / Cloud) – Absolute Katastrophe (Überlappungen, Durcheinander).
Ranking: Detailgrad & Inhaltliche Tiefe
- GPT-5.5 (OpenAI / Cloud) – Eigene Sektionen hinzugefügt, extrem detailliert.
- Qwen 3.6 27B (Lokal / Dense) – Hervorragende Präzision, komplette About-Sektion.
- Qwen 3.6 35B-A3B (Lokal / MoE) – Ähnlich hoher Detailgrad wie der 27B-Bruder.
- Gemma 4 31B (Lokal / Dense) – Ordentliches Basic-Niveau.
- Gemma 4 26B (Lokal / Dense) – Ordentliches Basic-Niveau.
- Gemini 3.1-Pro-Preview (Google / Cloud) – Sehr knapp, fehlende About-Sektion.
- Claude Opus 4.6 (Anthropic / Cloud) – Inhaltlich bemüht, aber durch Layout-Fehler unnutzbar.
Open Weight als echte Alternative: Mehr als nur ein Kompromiss
Der Test zeigt eines ganz deutlich: Lokale Open-Weight-Modelle sind längst kein Nischenprodukt mehr für Bastler oder datenschutzbesorgte Enthusiasten. Sie haben sich zu ernstzunehmenden Alternativen zu den etablierten Cloud-Giganten entwickelt – und Unternehmen sollten sie auch genau als solche behandeln.
Während Claude Opus 4.6 im rohen Testumfeld ohne helfenden Harness überraschend strauchelte und immense Kosten verursachte, zeigten Modelle wie Qwen 3.6 27B zeigten eindrucksvoll, was mit offener Technologie heute möglich ist. Sie bieten nicht nur absolute Unabhängigkeit und Datenhoheit, sondern liefern qualitativ Ergebnisse ab, die sich vor den Modellen von Google oder OpenAI nicht verstecken müssen. Wer die volle Kontrolle über seine Daten behalten, Vendor-Lock-ins vermeiden und dennoch auf modernstem Niveau entwickeln möchte, kommt an lokalen Open-Weight-Modellen heute nicht mehr vorbei.
Ausblick: Was kommt als Nächstes?
In Teil 2 unserer Serie werden wir den Fokus verschieben und die Modelle bei einer völlig neuen Aufgabe gegeneinander antreten lassen: Der Analyse von Finanzberichten. Hier wird sich zeigen, wie gut die Modelle mit fachspezifischem Kontext und echten Zahlen umgehen können.
Ein Aspekt, den wir in diesem aktuellen Test bewusst nicht geprüft haben, ist das Verhalten der Modelle bei stark wachsenden Kontext-Fenstern. Da dies ein enorm wichtiges Thema ist, wird es hierfür in der Zukunft noch einen eigenständigen, dedizierten Test geben. Bleibt gespannt!